library(nycflights13)
library(tidyverse)
if (!file.exists("data/hotels.csv")) {
download.file(url = "https://raw.githubusercontent.com/rstudio-education/datascience-box/main/course-materials/_slides/u2-d06-grammar-wrangle/data/hotels.csv",
destfile = "data/hotels.csv")
}
if (!file.exists("data/professions.csv")) {
download.file(url = "https://raw.githubusercontent.com/rstudio-education/datascience-box/main/course-materials/_slides/u2-d08-multi-df/data/professions.csv",
destfile = "data/professions.csv")
}
if (!file.exists("data/dates.csv")) {
download.file(url = "https://raw.githubusercontent.com/rstudio-education/datascience-box/main/course-materials/_slides/u2-d08-multi-df/data/dates.csv",
destfile = "data/dates.csv")
}
if (!file.exists("data/works.csv")) {
download.file(url = "https://raw.githubusercontent.com/rstudio-education/datascience-box/main/course-materials/_slides/u2-d08-multi-df/data/works.csv",
destfile = "data/qorks.csv")
}W#04: Relational Data, Math: Sets and Functions, Programming Functions
Working with more dataframes
- Data can be distributed in several dataframes which have relations which each other.
- For example, they share variables as the five dataframes in
nycflights13.
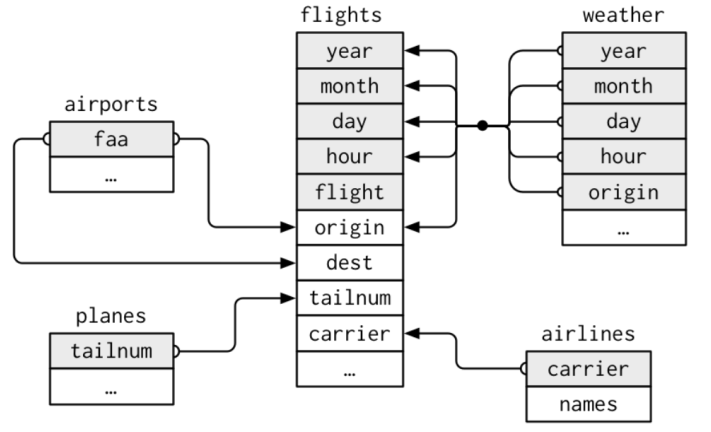
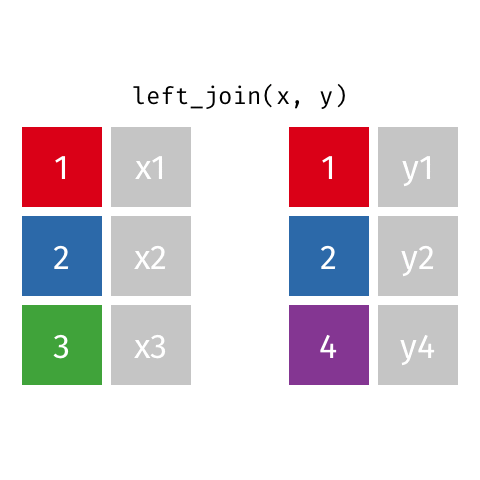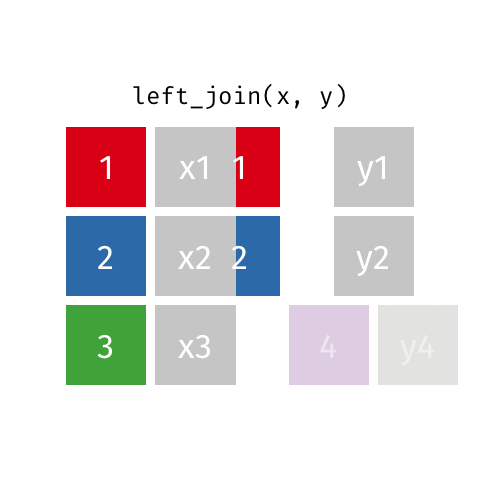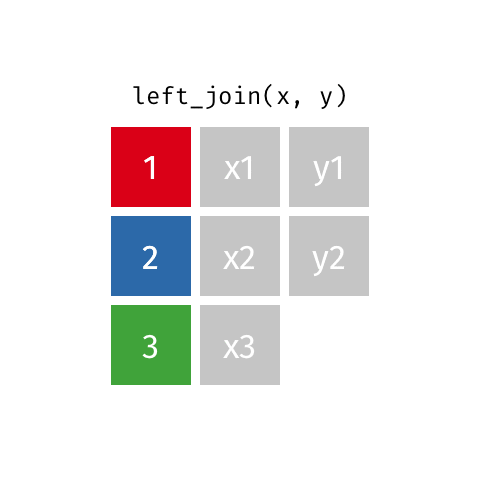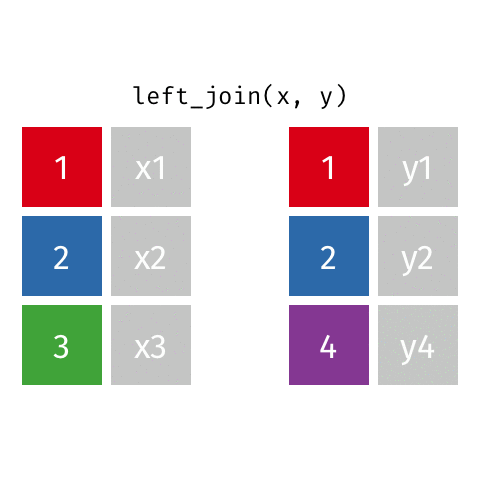
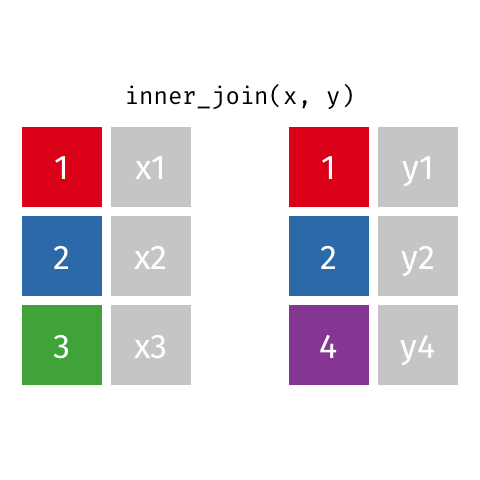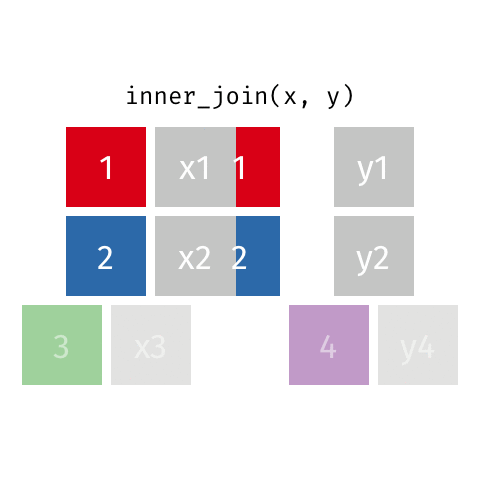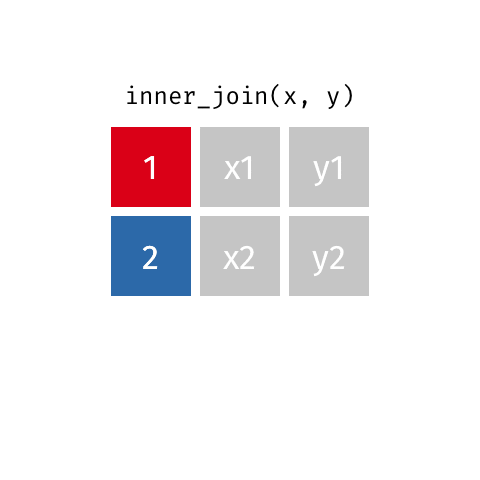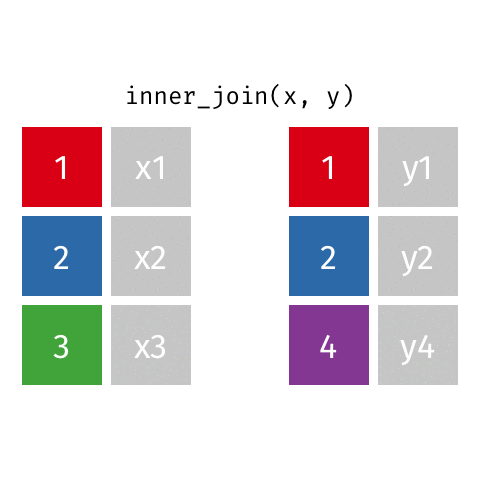
left_join()
right_join()
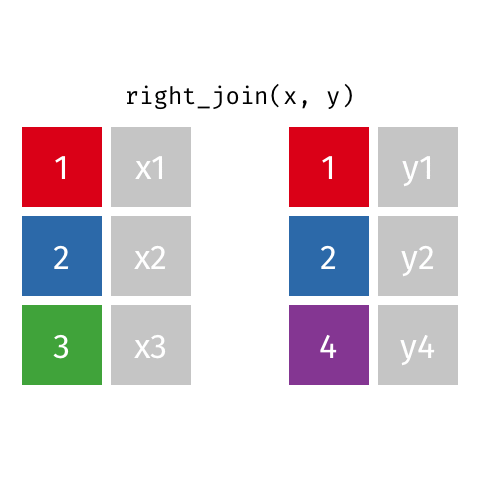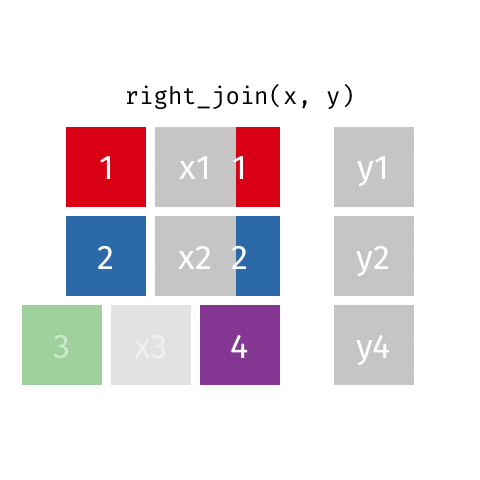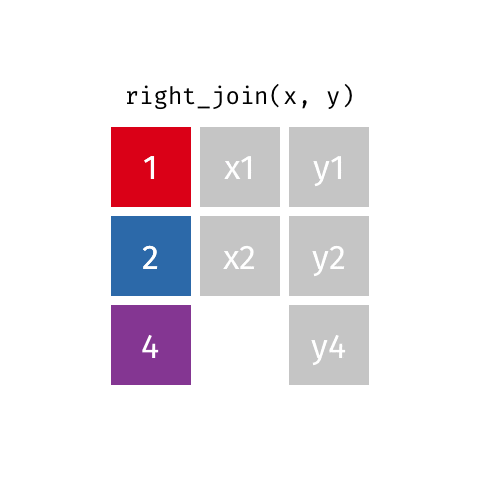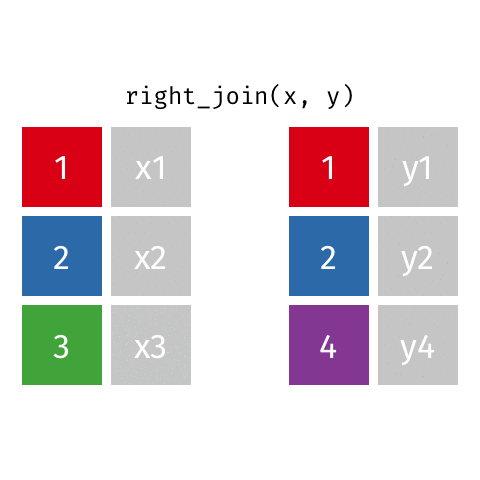
full_join()

inner_join()
Functions mathematically
Consider two sets: The domain \(X\) and the codomain \(Y\).
A function \(f\) assigns each element of \(X\) to exactly one element of \(Y\).
We write \(f : X \to Y\)
“\(f\) maps from \(X\) to \(Y\)”
and \(x \mapsto f(x)\)
“\(x\) maps to \(f(x)\)”
The yellow set is called the image of \(f\).

Is this a mathematical function?
 \(\ \mapsto\ \)
\(\ \mapsto\ \) 
Input from \(X = \{\text{A picture where a face can be recognized}\}\).
Function: Upload input at https://funny.pho.to/lion/ and download output.
Output from \(Y = \{\text{Set of pictures with a specific format.}\}\)
Yes, it is a function. Important: Output is the same for the same input!
Is this a mathematical function?
Input a text snippet. Function: Enter text at https://www.craiyon.com. Output a picture.

Other examples:
- “Nuclear explosion broccoli”
- “The Eye of Sauron reading a newspaper”
- “The legendary attack of Hamster Godzilla wearing a tiny Sombrero”
![]()


No, it is not a function. It has nine outcomes and these change when run again.
Graphs of functions
- A function is characterized by the set all possible pairs \((x,f(x))\).
- This is called its graph.
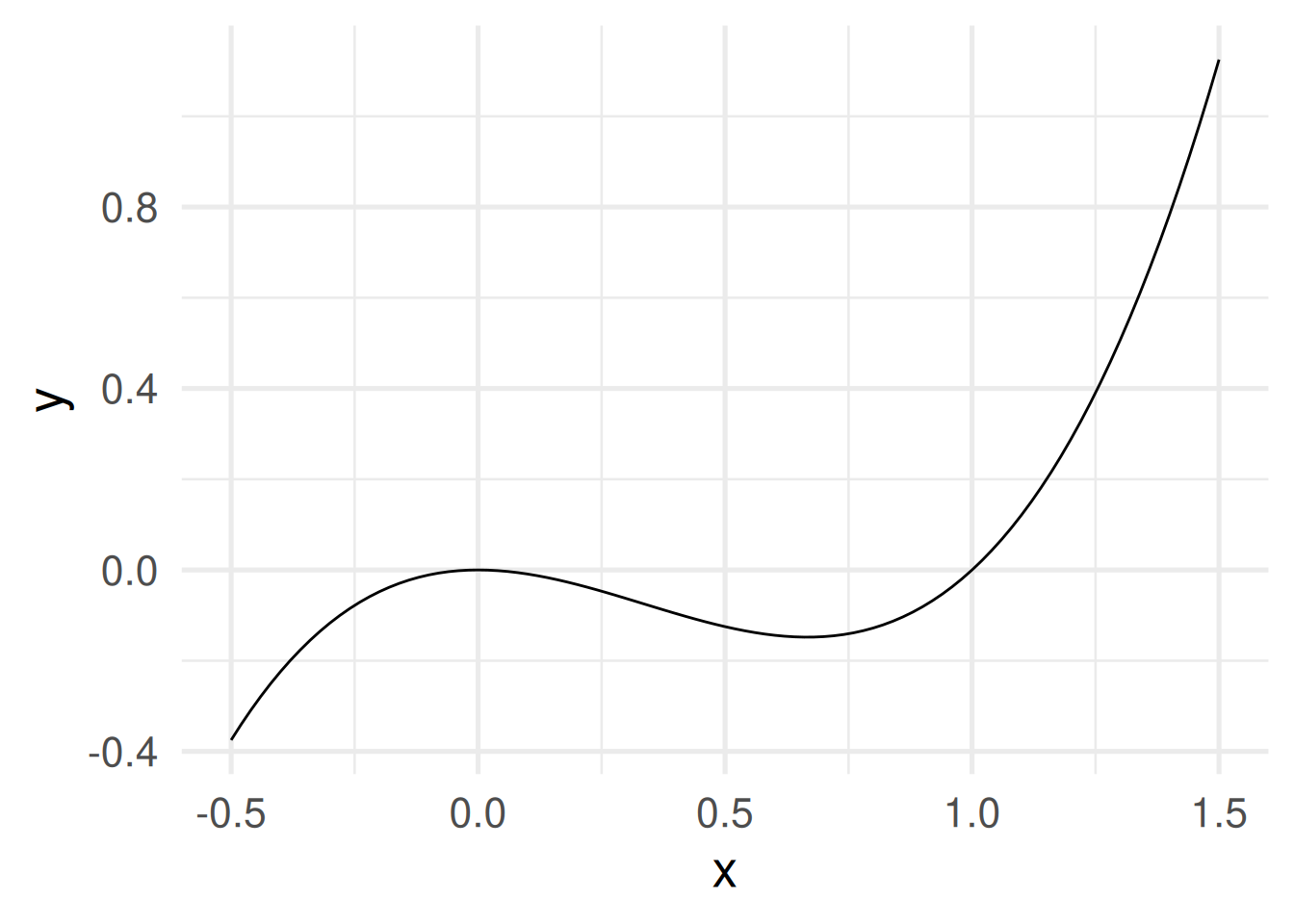
- When domain and codomain are real numbers then the graph can be shown in a Cartesian coordinate system. Example \(f(x) = x^3 - x^2\)
Some functions \(f: \mathbb{R} \to \mathbb{R}\)
\(f(x) = x\) identity function
\(f(x) = x^2\) square function
\(f(x) = \sqrt{x}\) square root function
\(f(x) = e^x\) exponential function
\(f(x) = \log(x)\) natural logarithm
- Square and square root function are inverse of each other. Exponential and natural logarithm, too.
\(\sqrt[2]{x}^2 = \sqrt[2]{x^2} = x\), \(\log(e^x) = e^{\log(x)} = x\)
- Identity function graph as mirror axis.
ggplot() +
geom_function(fun = function(x) x) +
geom_function(fun = function(x) exp(x), color = "red") +
geom_function(fun = function(x) log(x), color = "green") +
geom_function(fun = function(x) x^2, color = "orange") +
geom_function(fun = function(x) sqrt(x), color = "blue") +
coord_fixed() +
xlim(c(-3,3))+ ylim(c(-3,3)) + xlab("x") + theme_minimal(base_size = 20)Warning in log(x): NaNs producedWarning in sqrt(x): NaNs producedWarning: Removed 32 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 50 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 44 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 50 rows containing missing values or values outside the scale range
(`geom_function()`).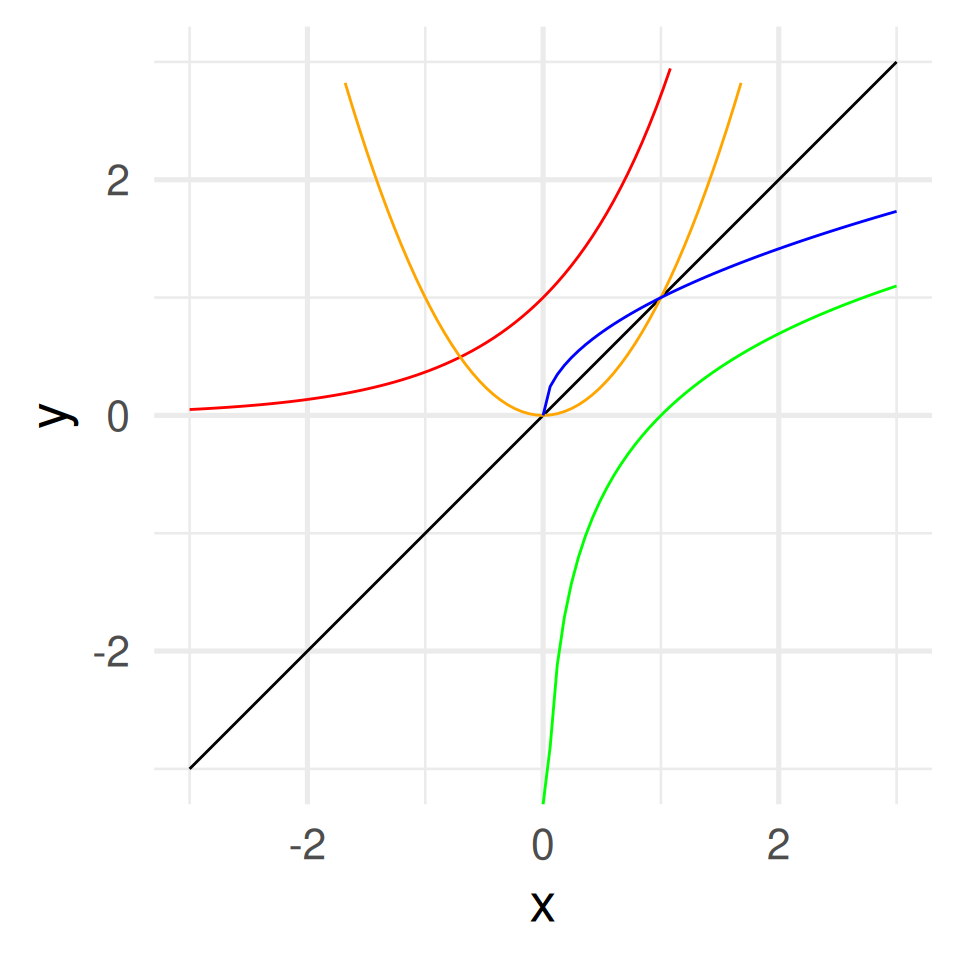
Shifts and scales
How can we shift, stretch, or shrink a graph vertically and horizontally?
Add a constant to the function.
\(f(x) = x^3 - x^2 \leadsto\)
\(\quad f(x) = x^3 - x^2 + a\)
For \(a =\) -2, -0.5, 0.5, 2
a = c(1, 0.5, 2, -0.5, -2)
ggplot() + geom_function(fun = function(x) x^3 - x^2, size = 2, alpha = 0.5) +
geom_function(fun = function(x) x^3 - x^2 +a[2], color = "blue4", size = 2) +
geom_function(fun = function(x) x^3 - x^2 +a[3], color = "blue", size = 2) +
geom_function(fun = function(x) x^3 - x^2 +a[4], color = "red4") +
geom_function(fun = function(x) x^3 - x^2 +a[5], color = "red") +
coord_fixed() + xlim(c(-3,3)) + ylim(c(-3,3)) + xlab("x") + theme_minimal(base_size = 24)Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.Warning: Removed 50 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 51 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 53 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 50 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 53 rows containing missing values or values outside the scale range
(`geom_function()`).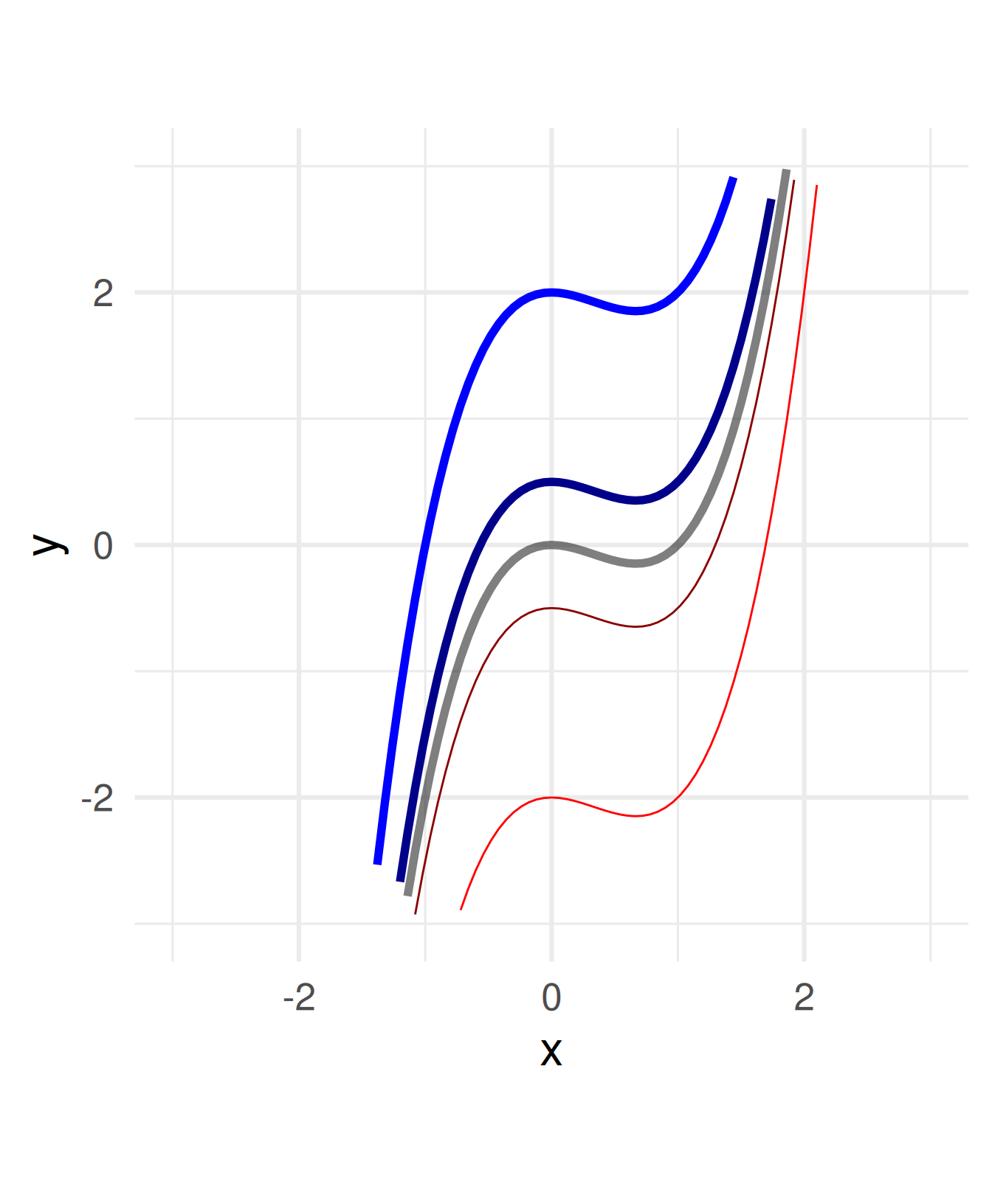
Subtract a constant from all \(x\) within the function definition.
\(f(x) = x^3 - x^2 \leadsto\)
\(\quad f(x) = (x - a)^3 - (x - a)^2\)
For \(a =\) -2, -0.5, 0.5, 2
Attention:
Shifting \(a\) units to the right needs subtracting \(a\)!
You can think of the coordinate system being shifted in direction \(a\) while the graph stays.
a = c(1, 0.5, 2, -0.5, -2)
ggplot() + geom_function(fun = function(x) x^3 - x^2, size = 2, alpha = 0.5) +
geom_function(fun = function(x) (x-a[2])^3 - (x-a[2])^2, color = "blue4", size = 2) +
geom_function(fun = function(x) (x-a[3])^3 - (x-a[3])^2, color = "blue", size = 2) +
geom_function(fun = function(x) (x-a[4])^3 - (x-a[4])^2, color = "red4") +
geom_function(fun = function(x) (x-a[5])^3 - (x-a[5])^2, color = "red") +
coord_fixed() + xlim(c(-3,3)) + ylim(c(-3,3)) + xlab("x") + theme_minimal(base_size = 24)Warning: Removed 50 rows containing missing values or values outside the scale range
(`geom_function()`).
Removed 50 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 64 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 51 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 53 rows containing missing values or values outside the scale range
(`geom_function()`).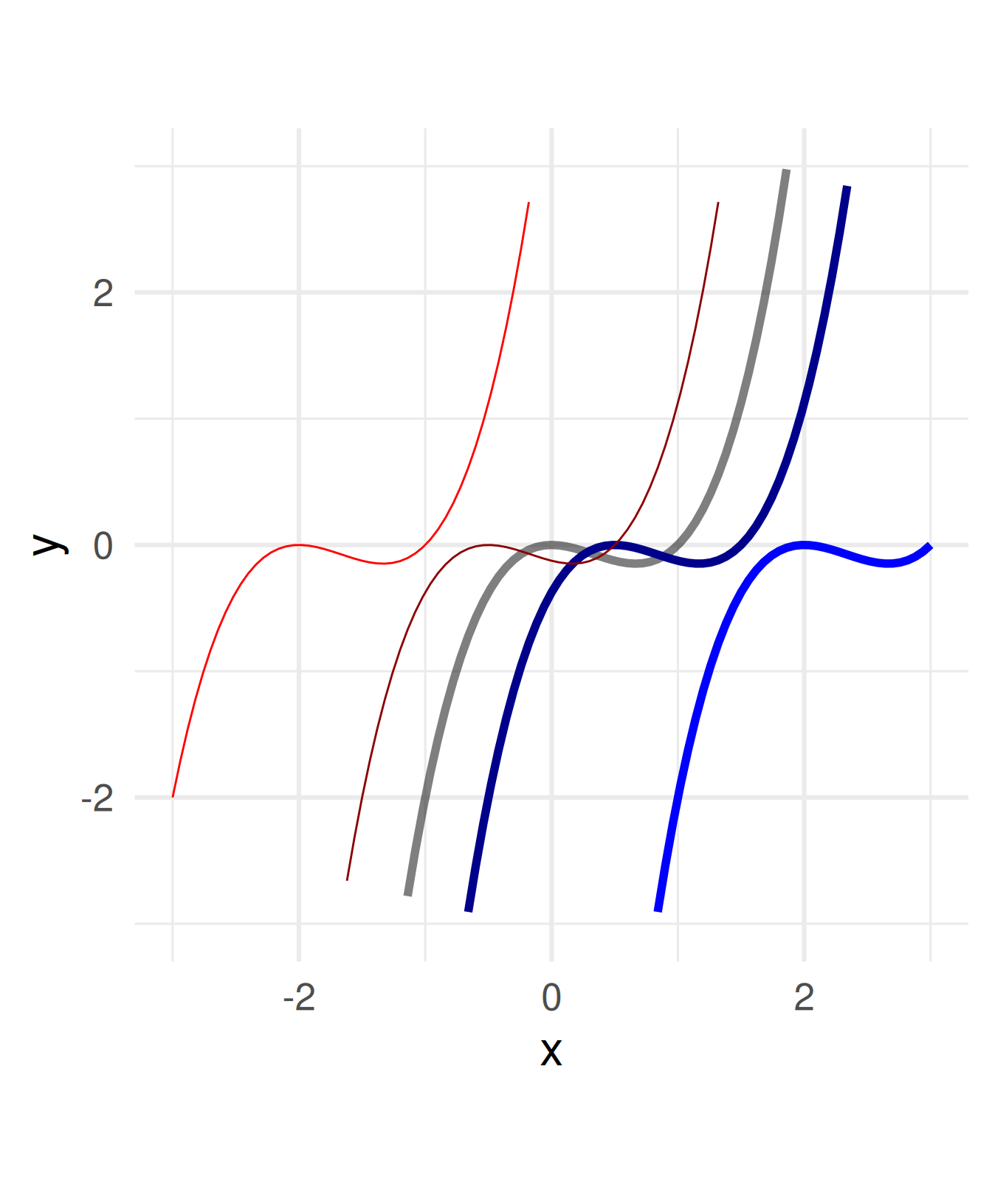
Multiply a constant to all \(x\) within the function definition.
\(f(x) = x^3 - x^2 \leadsto\)
\(\quad f(x) = a(x^3 - x^2)\)
For \(a =\) -2, -0.5, 0.5, 2
Negative numbers flip the graph around the \(x\)-axis.
a = c(1, 0.5, 2, -0.5, -2)
ggplot() + geom_function(fun = function(x) x^3 - x^2, size = 2, alpha = 0.5) +
geom_function(fun = function(x) a[2]*((x)^3 - (x)^2), color = "blue4", size = 2) +
geom_function(fun = function(x) a[3]*((x)^3 - (x)^2), color = "blue", size = 2) +
geom_function(fun = function(x) a[4]*((x)^3 - (x)^2), color = "red4") +
geom_function(fun = function(x) a[5]*((x)^3 - (x)^2), color = "red") +
coord_fixed() + xlim(c(-3,3)) + ylim(c(-3,3)) + xlab("x") + theme_minimal(base_size = 24)Warning: Removed 50 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 39 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 60 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 39 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 60 rows containing missing values or values outside the scale range
(`geom_function()`).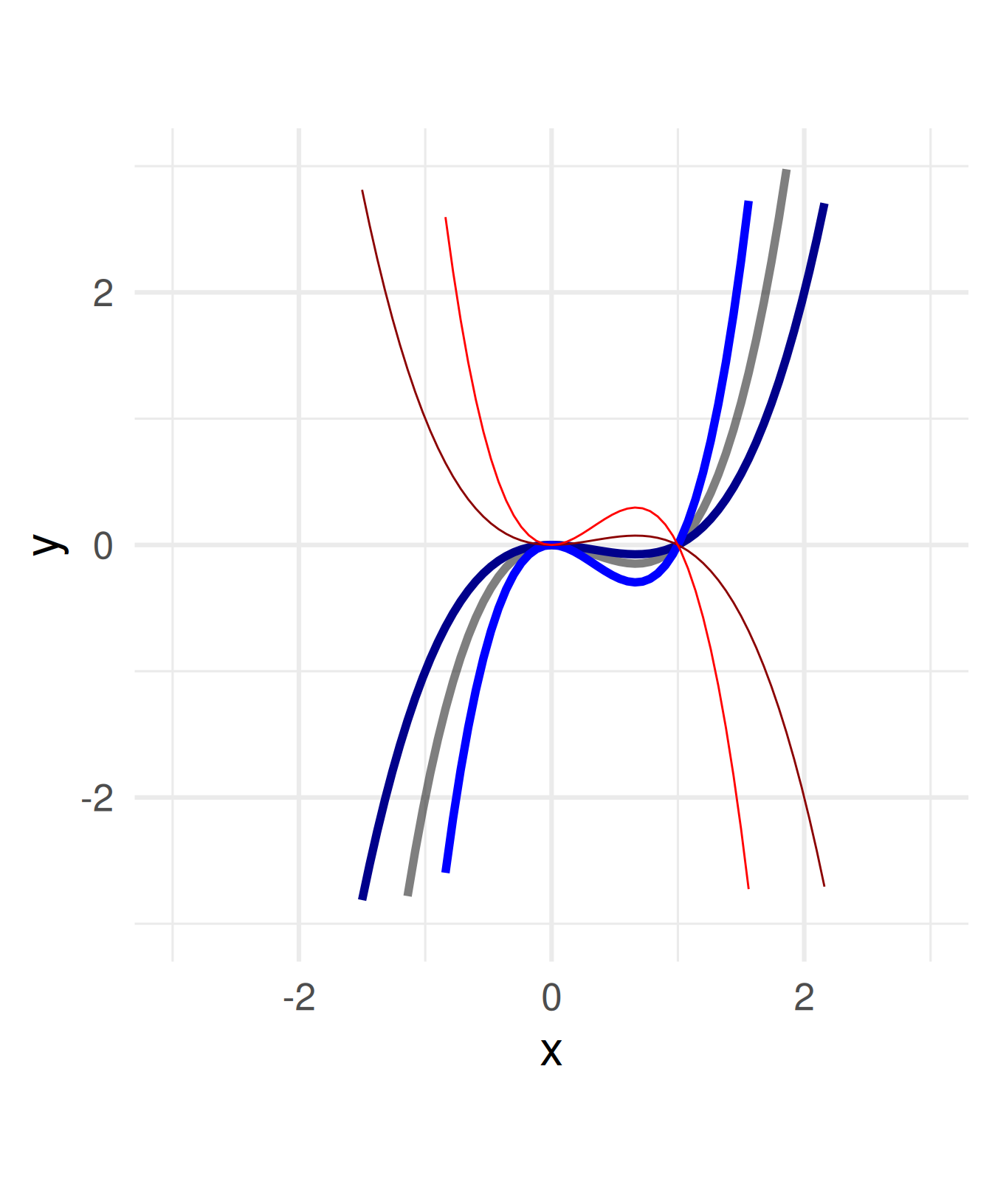
Divide all \(x\) within the function definition by a constant.
\(f(x) = x^3 - x^2 \leadsto\)
\(\quad f(x) = (x/a)^3 - (x/a)^2\)
For \(a =\) -2, -0.5, 0.5, 2
Negative numbers flip the graph around the \(y\)-axis.
Attention: Stretching needs a division by \(a\)!
You can think of the coordinate system being stretched multiplicatively by \(a\) while the graph stays.
a = c(1, 0.5, 2, -0.5, -2)
ggplot() + geom_function(fun = function(x) x^3 - x^2, size = 2, alpha = 0.5) +
geom_function(fun = function(x) (x/a[2])^3 - (x/a[2])^2, color = "blue4", size = 2) +
geom_function(fun = function(x) (x/a[3])^3 - (x/a[3])^2, color = "blue", size = 2) +
geom_function(fun = function(x) (x/a[4])^3 - (x/a[4])^2, color = "red4") +
geom_function(fun = function(x) (x/a[5])^3 - (x/a[5])^2, color = "red") +
coord_fixed() + xlim(c(-3,3)) + ylim(c(-3,3)) + xlab("x") + theme_minimal(base_size = 24)Warning: Removed 50 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 76 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 11 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 76 rows containing missing values or values outside the scale range
(`geom_function()`).Warning: Removed 11 rows containing missing values or values outside the scale range
(`geom_function()`).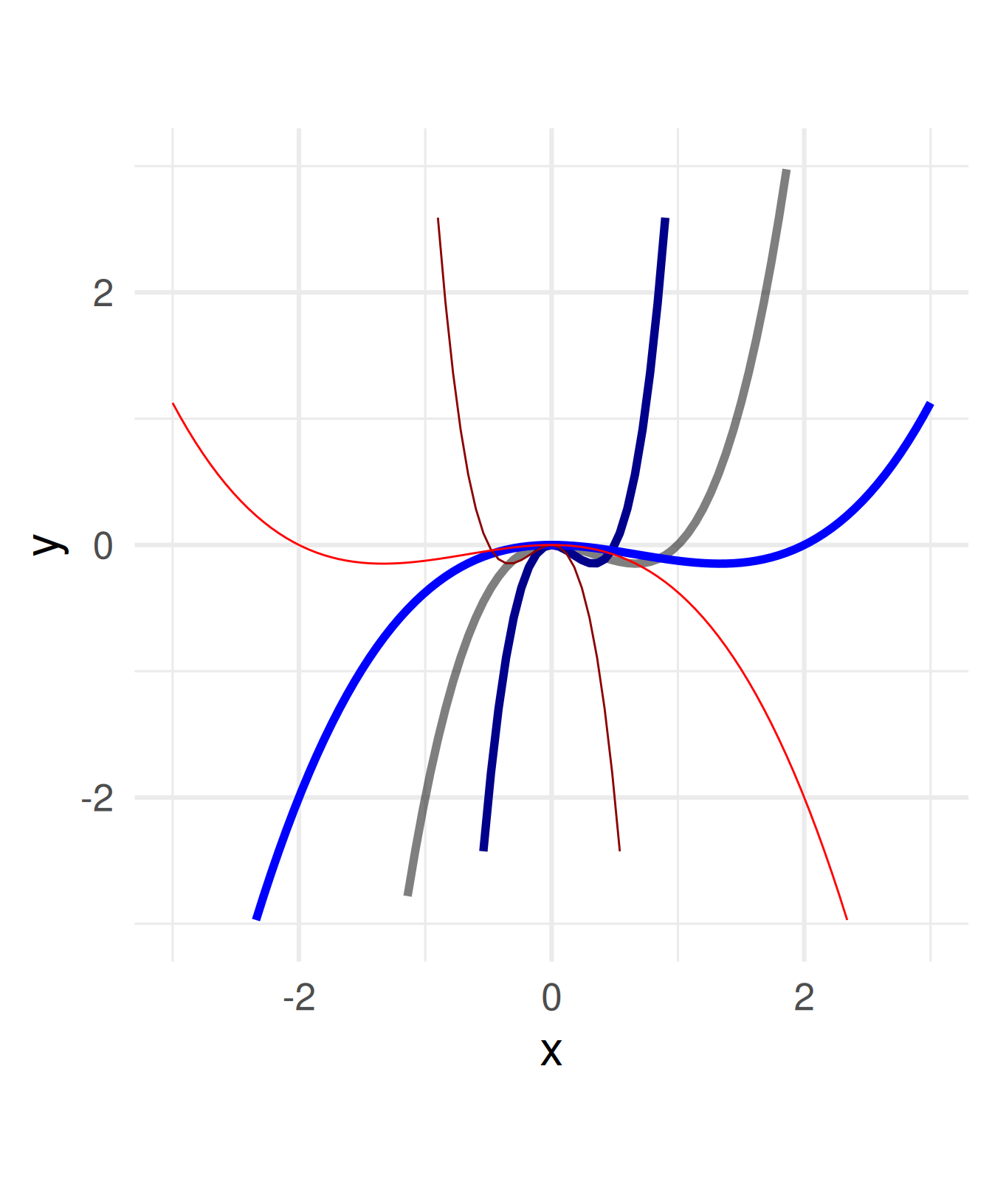
Math: Polynomials and exponentials
A polynomial is a function which is composed of (many) addends of the form \(ax^n\) for different values of \(a\) and \(n\).
In an exponential the \(x\) appears in the exponent.
\(f(x) = x^3\) vs. \(f(x) = e^x\)
library(patchwork)
g1 = ggplot() +
geom_function(fun = function(x) x^3) +
geom_function(fun = function(x) exp(x)-1, color = "red") +
xlim(c(0,2)) + xlab("x") + theme_minimal(base_size = 18)
g2 = g1 + xlim(c(0,5))Scale for x is already present.
Adding another scale for x, which will replace the existing scale.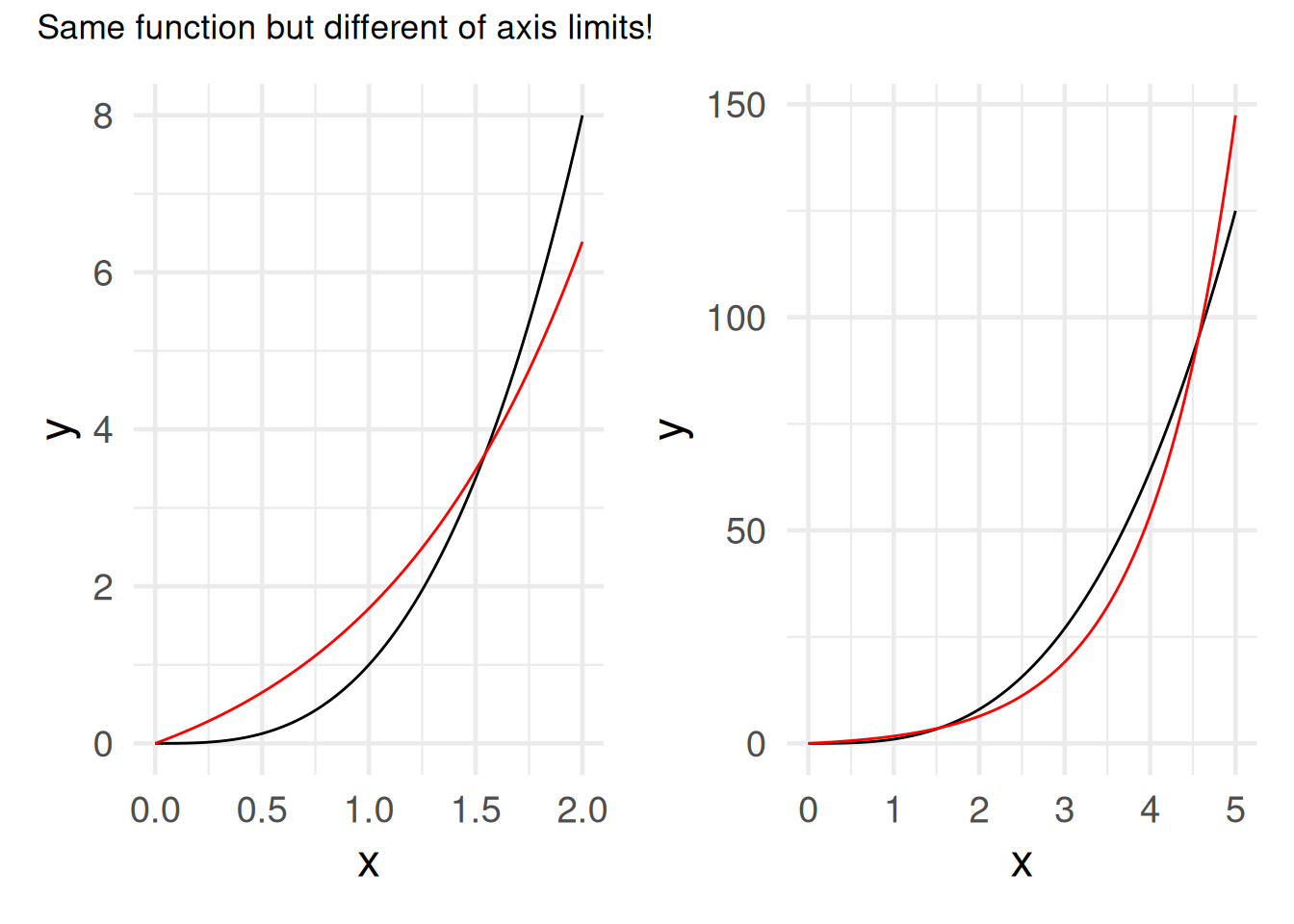
For \(x\to\infty\), any exponential will finally “overtake” any polynomial.
Input \(\to\) output

- Metaphorically, a function is a machine or a blackbox that for each input yields an output.
- The inputs of a function are also called arguments.
Difference to math terminolgy:
The output need not be the same for the same input.
Plotting and transformation
Vector creation and vectorized functions are key for plotting and transformation.
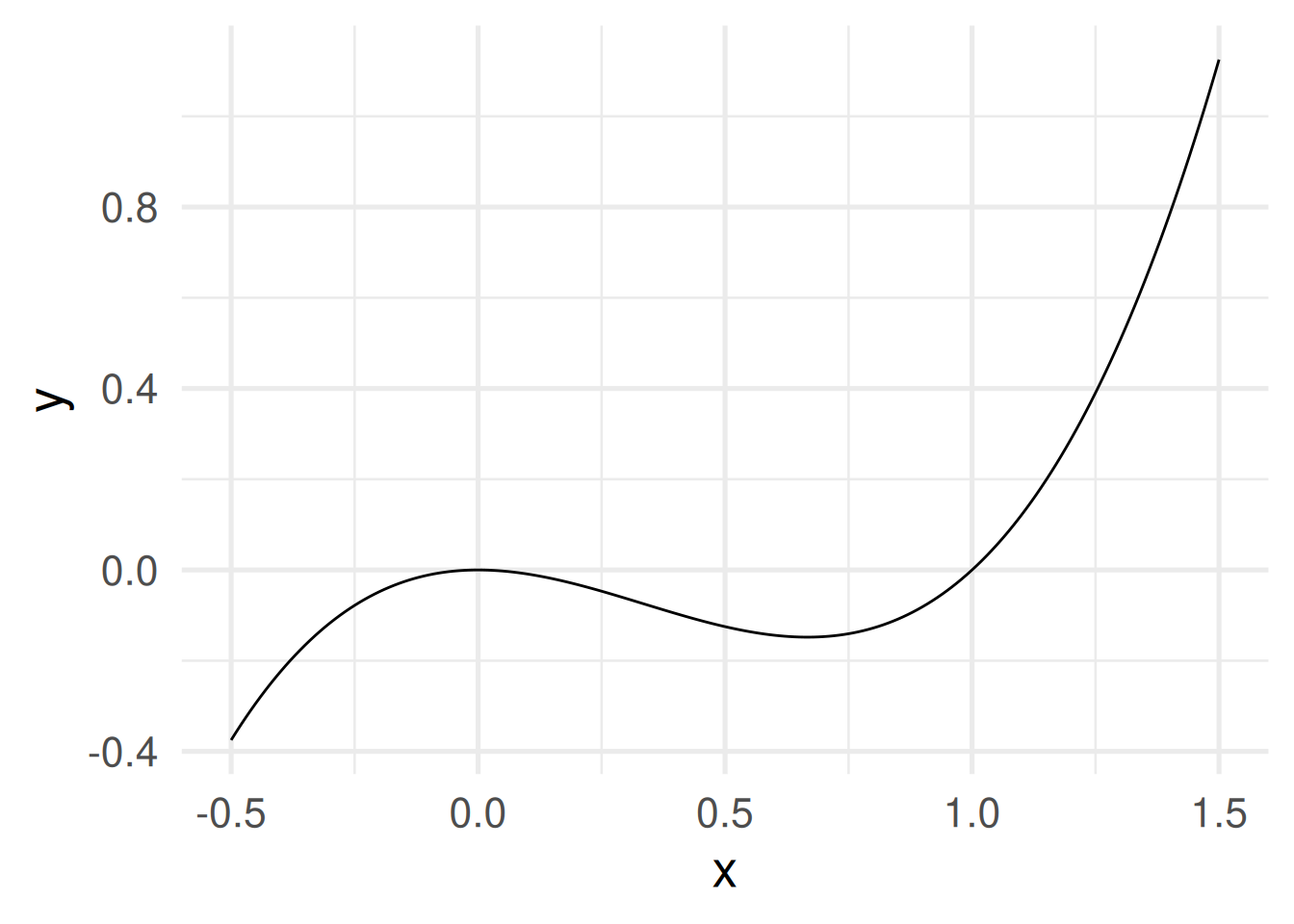
Conveniently ggploting functions
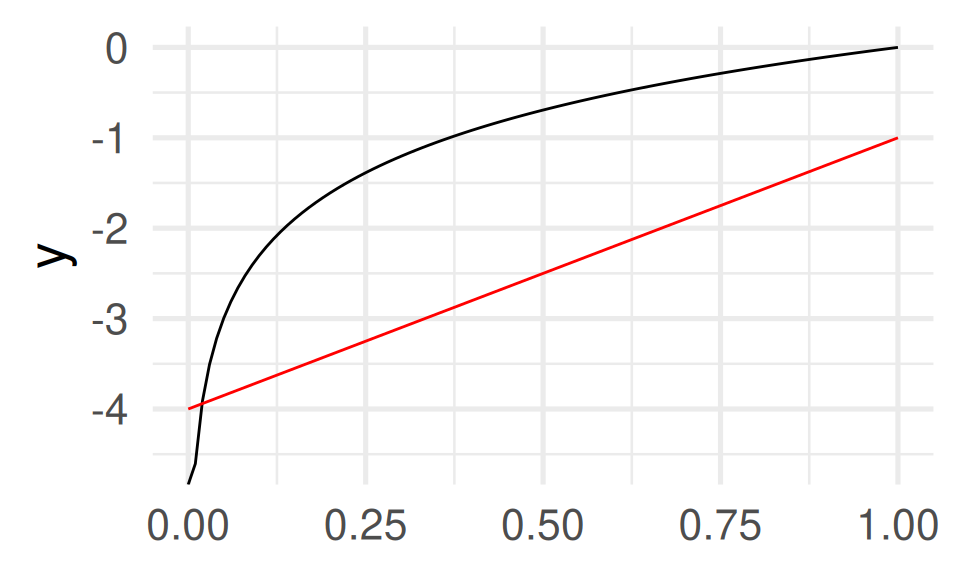
Code line 3 shows another important concept: anonymous functions. The function function(x) 3*x - 4 is defined on the fly without a name.
Vectorized operations with map
mapfunctions apply a function to each element of a vector.1map(.x, .f, ...)applies the function.fto each element of the vector of.xand returns a list.map_dblreturns a double vector (other variants exist)
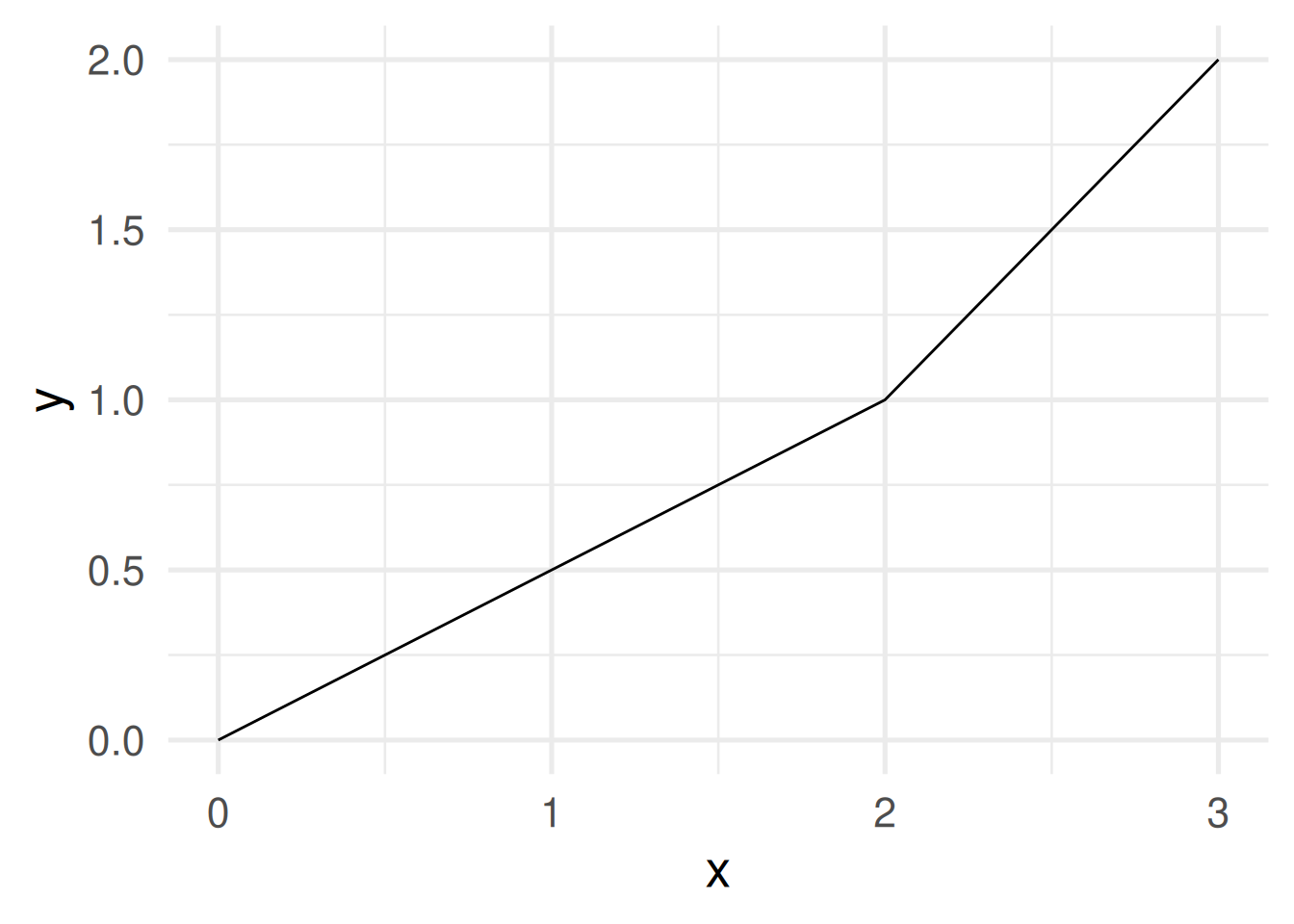
Function programming: Take away
- Functions are the most important building blocks of programming.
- Functions can and often should be vectorized.
- Vectorized functions are the basis for plotting and transformation.
mapfunctions are powerful tools for iterative tasks!
Expect to not get the idea first but to love them later.
