W#08: Predicting Categorical Variables, Logistic Regression, Classification Problems
Data exploration
Would you expect spam to be longer or shorter?

Would you expect spam subject to start with “Re:” or the like?

Linear models?
Both seem to give some signal. How can we model the relationship?
We focus first on just num_char:
email |> ggplot(aes(x = num_char, y = as.numeric(spam)-1)) +
geom_point(alpha = 0.2) + geom_smooth(method = "lm")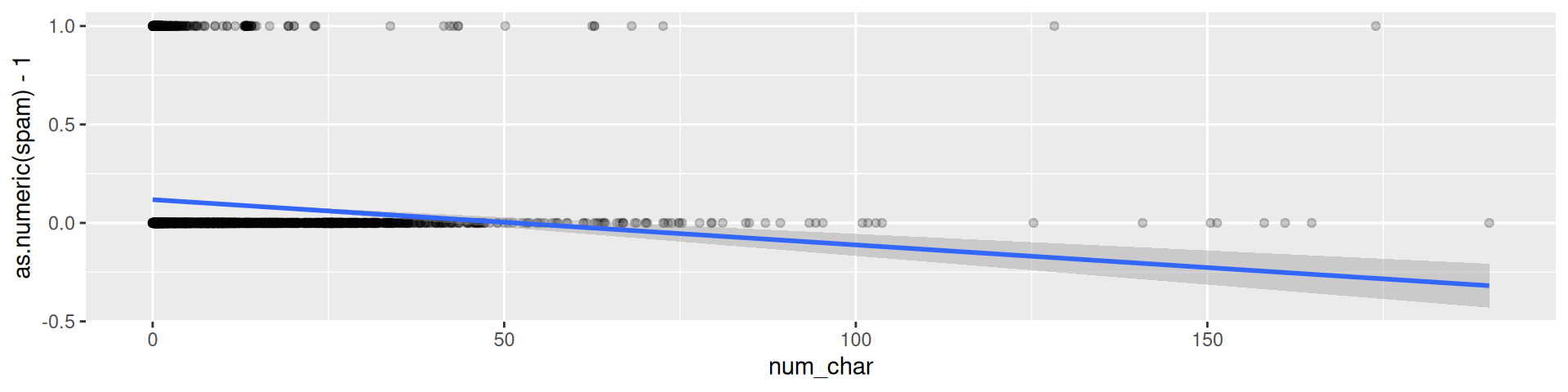
We would like to have a better concept!
A penguins example - predict sex

It does not make much sense to predict 0-1-values with a linear model.
Logit and logistic function
ggplot() +
geom_vline(xintercept = 0) + geom_hline(yintercept = 0) + geom_abline(intercept = 0, linetype = "dotted") +
geom_vline(xintercept = 1, linetype = "dashed") + geom_hline(yintercept = 1, linetype = "dashed") +
geom_function(fun = function(x) log(x/(1-x)), xlim=c(0.001,0.999), n = 500, color = "blue") +
geom_function(fun = function(x) 1/(1 + exp(-x)), color = "red") +
scale_x_continuous(breaks = seq(-4,4,1), limits = c(-4,4)) +
scale_y_continuous(breaks = seq(-4,4,1), limits = c(-4,4)) +
coord_fixed() + theme_minimal(base_size = 24) + labs(x = "x")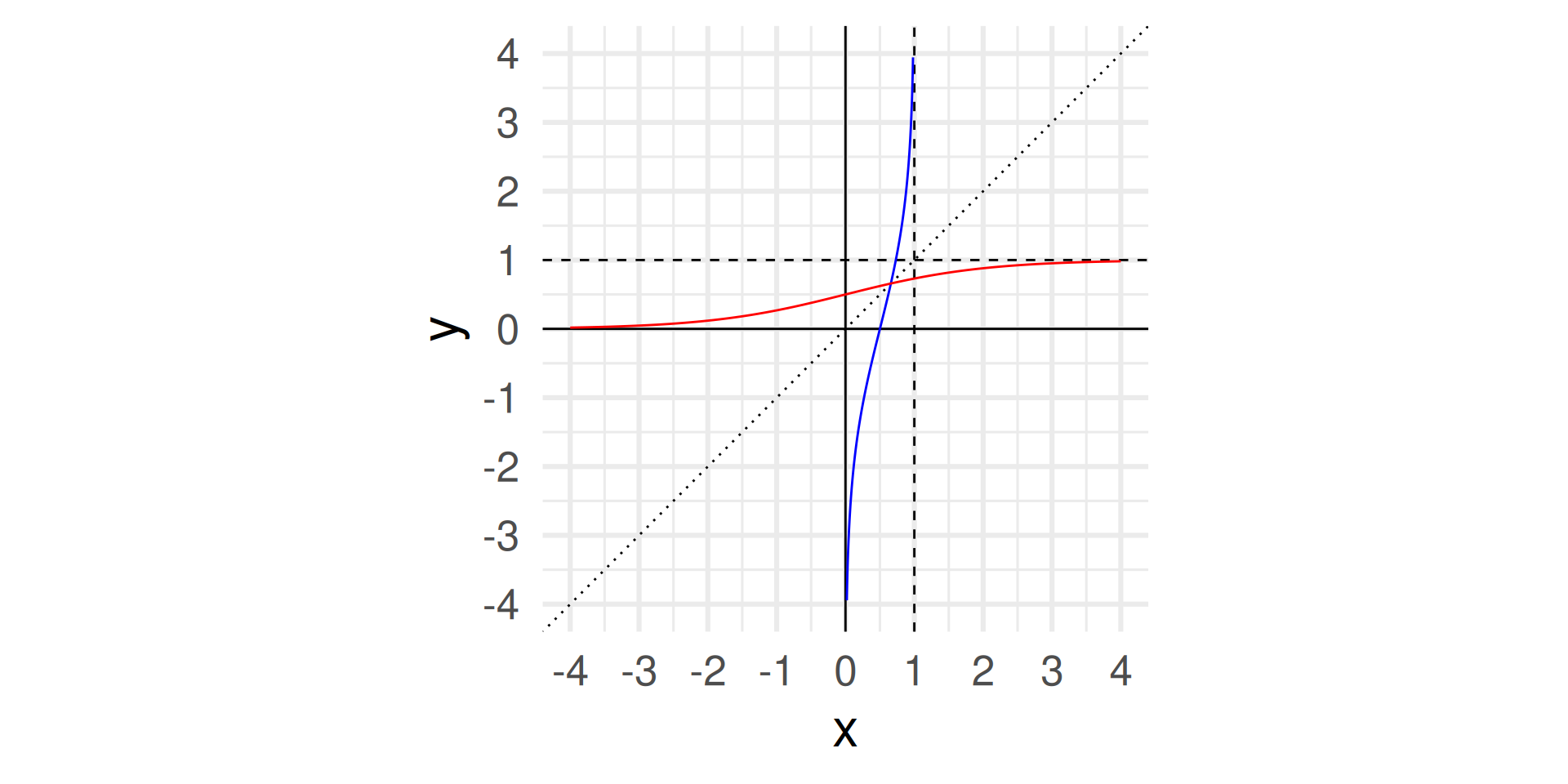
Predicted probability
logistic <- function(t) 1/(1+exp(-t))
preds <- tibble(x=c(2,15,40), y = logistic(-1.80-0.0621*x))
email |> ggplot(aes(x = num_char, y = as.numeric(spam)-1)) +
geom_point(alpha = 0.2) +
geom_function(fun = function(x) logistic(-1.80-0.0621*x),color="red") +
geom_point(data = preds, mapping = aes(x,y), color = "blue", size = 3)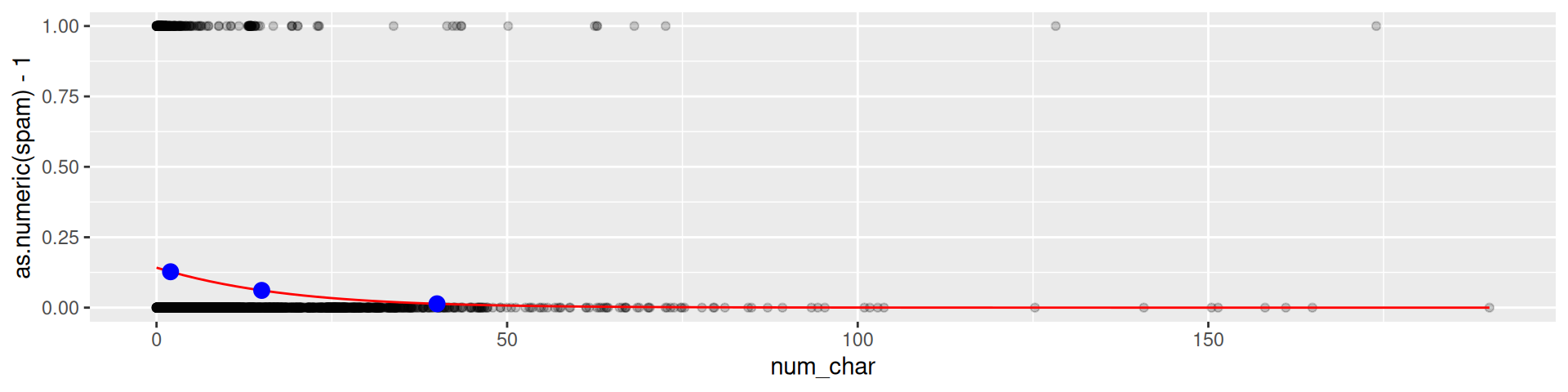
Spam probability 2,000 characters: 0.1273939
Spam probability 15,000 characters: 0.06114
Spam probability 40,000 characters: 0.0135999
Penguins example
library(palmerpenguins)
sex_fit <- logistic_reg() |>
set_engine("glm") |>
fit(sex ~ body_mass_g, data = na.omit(penguins), family = "binomial")
tidy(sex_fit)# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -5.16 0.724 -7.13 1.03e-12
2 body_mass_g 0.00124 0.000173 7.18 7.10e-13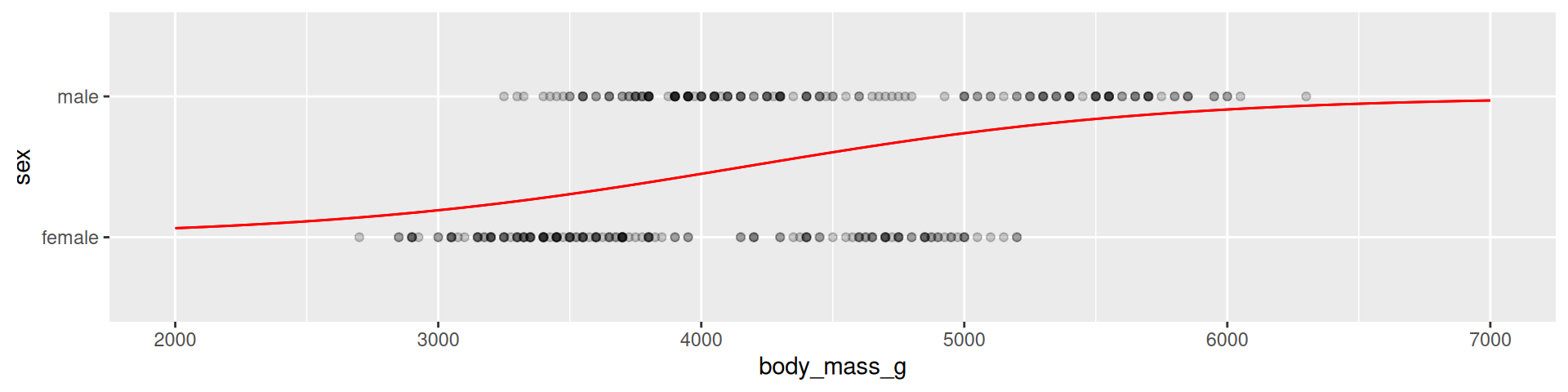
Confusion matrix
More general: Confusion matrix of statistical classification:

Sensitivity and specificity
Sensitivity is the true positive rate: TP / (TP + FN)
Specificity is the true negative rate: TN / (TN + FP)
For spam a positive case is an email labelled as spam:
Sensitivity: Fraction of emails labelled as spam among all emails which are spam.
Low sensitivity \(\to\) More false negatives \(\to\) More spam in you inbox!
Specificity: Fraction of emails labelled as not spam among all emails which are not spam.
Low specificity \(\to\) More false positives \(\to\) More relevant emails in spam folder!
If you were designing a spam filter, would you want sensitivity and specificity to be high or low? What are the trade-offs associated with each decision?
Another view

Balance Over- and Underfitting
In a one predictor model we can show both visually (This is simulated data)
Code
lm_fit <- linear_reg() |>
set_engine("lm") |>
fit(y4 ~ x2, data = association)
loess_fit <- loess(y4 ~ x2, data = association)
loess_overfit <- loess(y4 ~ x2, span = 0.05, data = association)
association |>
select(x2, y4) |>
mutate(
Underfit = augment(lm_fit$fit) |> select(.fitted) |> pull(),
OK = augment(loess_fit) |> select(.fitted) |> pull(),
Overfit = augment(loess_overfit) |> select(.fitted) |> pull(),
) |>
pivot_longer(
cols = Underfit:Overfit,
names_to = "fit",
values_to = "y_hat"
) |>
mutate(fit = fct_relevel(fit, "Underfit", "OK", "Overfit")) |>
ggplot(aes(x = x2)) +
geom_point(aes(y = y4), color = "darkgray") +
geom_line(aes(y = y_hat, group = fit, color = fit), size = 1) +
labs(x = NULL, y = NULL, color = NULL) +
scale_color_viridis_d(option = "plasma", end = 0.7)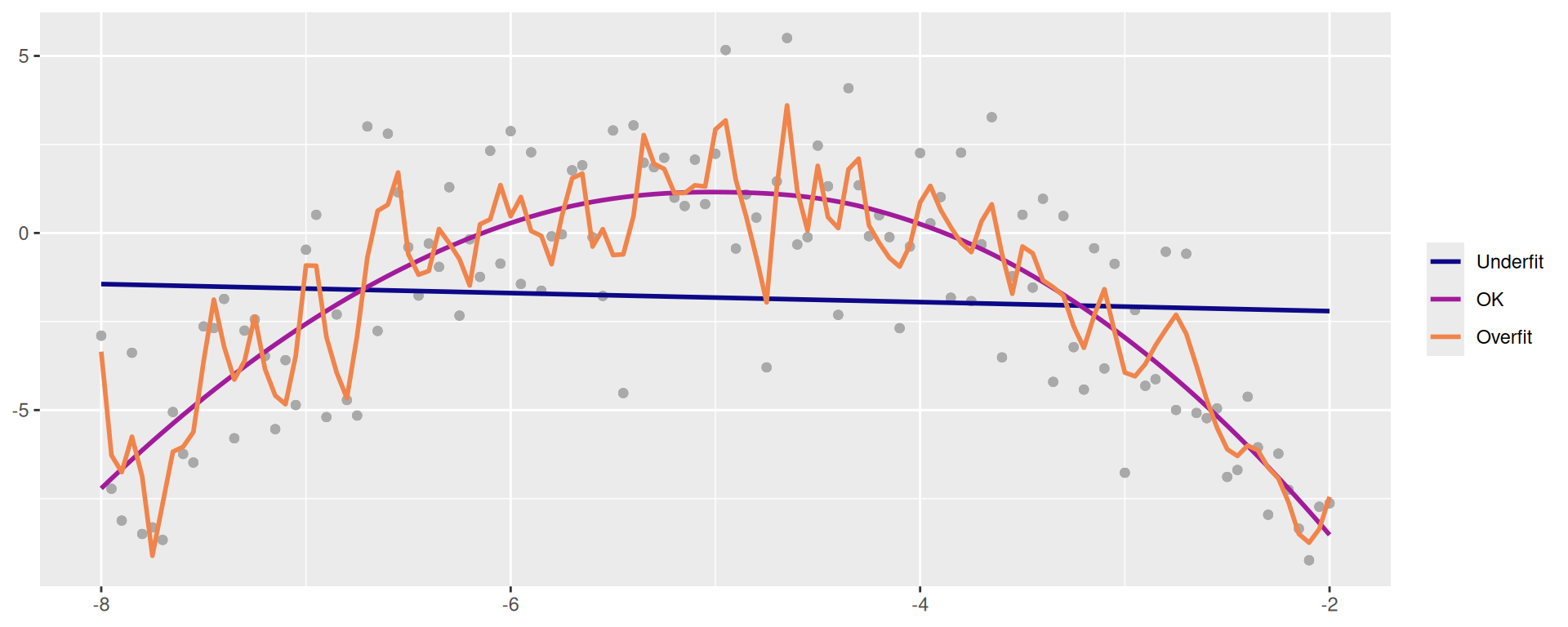
Look at categorical predictors
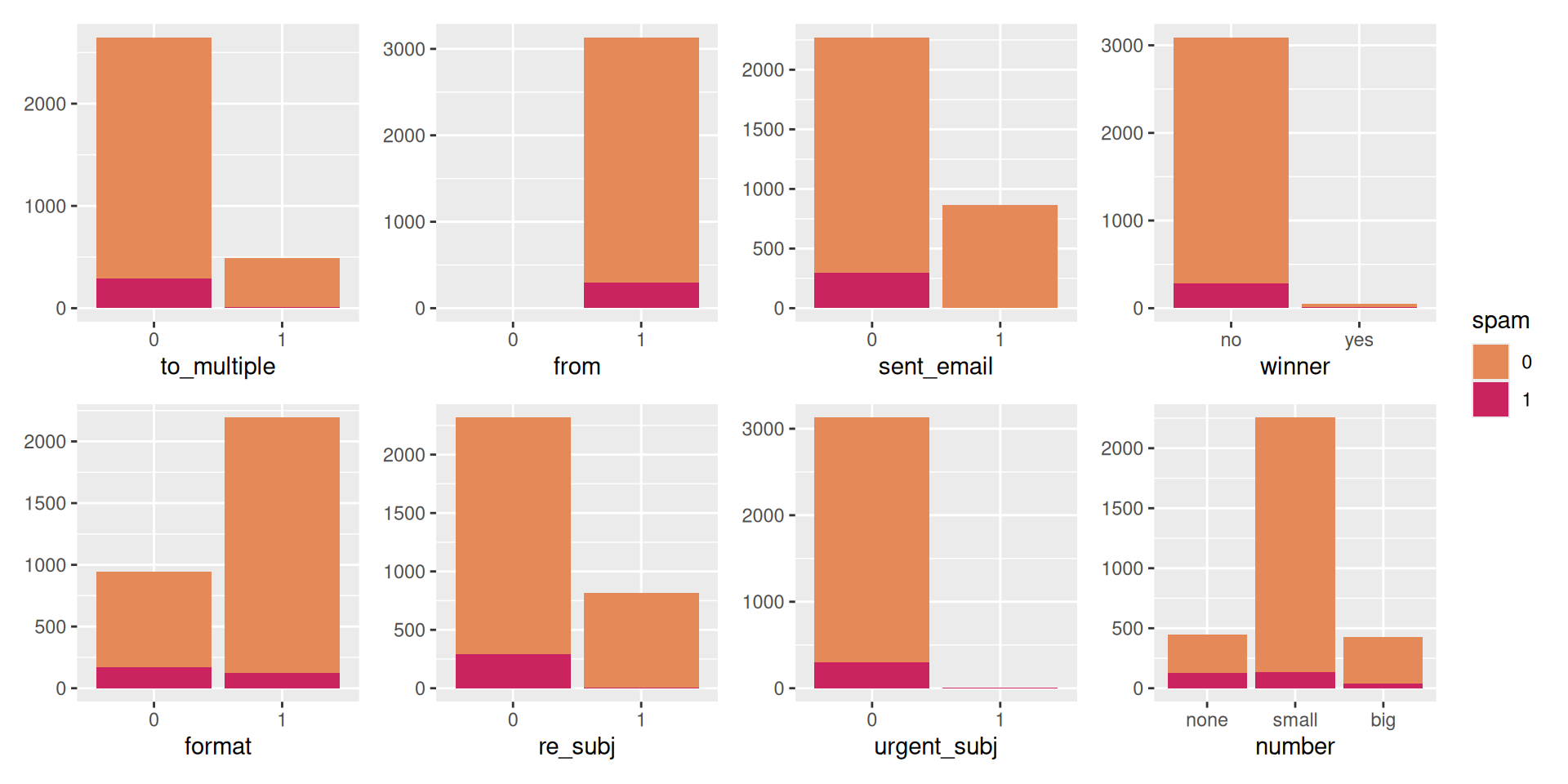
Closer look at from and sent_email.
Evaluate performance: ROC curve
Receiver operating characteristic (ROC) curve1 which plots true positive rate (sensitivity) vs. false positive rate (1 - specificity)
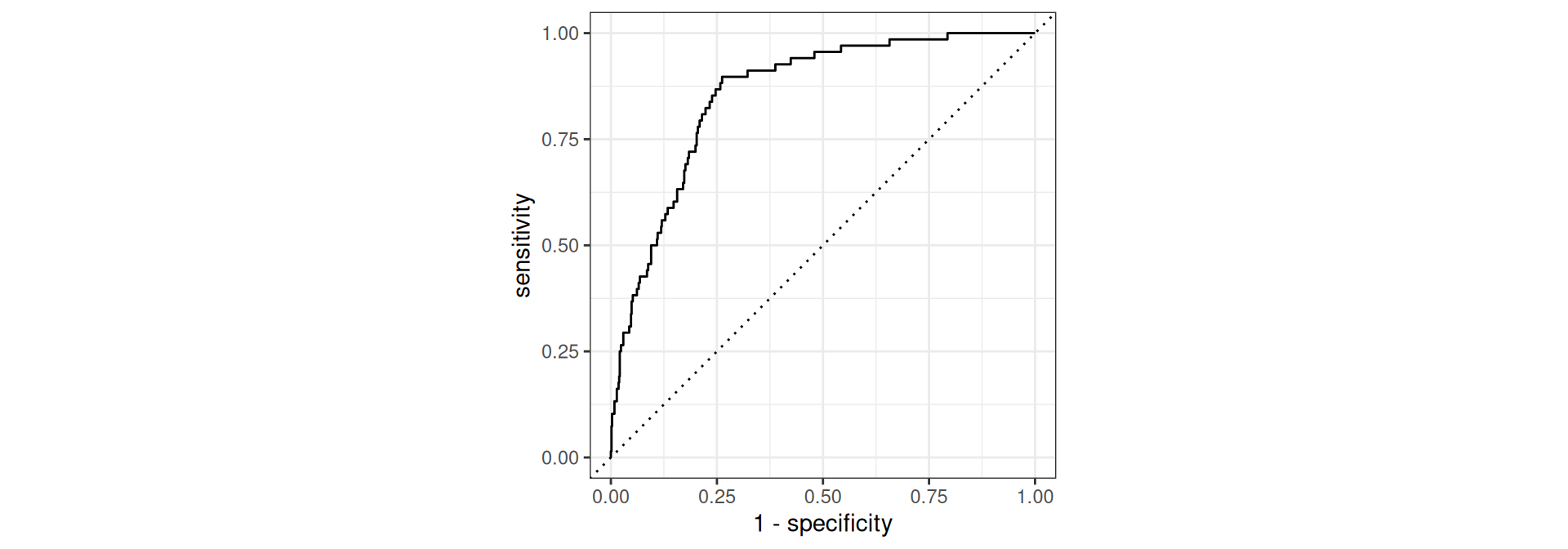
ROC curve
Code
email_pred_roc <- email_pred |> roc_curve(
truth = spam, spam_prob,
event_level = "second" # this adjusts the location above the diagonal
)
email_pred_roc_thresholds <- email_pred_roc |>
mutate(.threshold_rounded = round(.threshold, digits = 2)) |>
filter(.threshold_rounded == 0.25 | .threshold_rounded == 0.5 | .threshold_rounded == 0.75)
email_pred_roc |>
ggplot(aes(x = 1 - specificity, y = sensitivity)) + geom_line() +
geom_point(data = email_pred_roc |> slice(round(seq(30,nrow(email_pred_roc)-30, length.out = 10))),
color = "black") +
geom_text(data = email_pred_roc |> slice(round(seq(30,nrow(email_pred_roc)-30, length.out = 10))),
mapping = aes(label = round(.threshold, digits = 2)),
color = "black",
nudge_x = 0.04,
nudge_y = -0.03, size = 3) +
geom_abline(lty = 3) +
labs(title = "ROC-curve") +
coord_equal() +
theme_bw()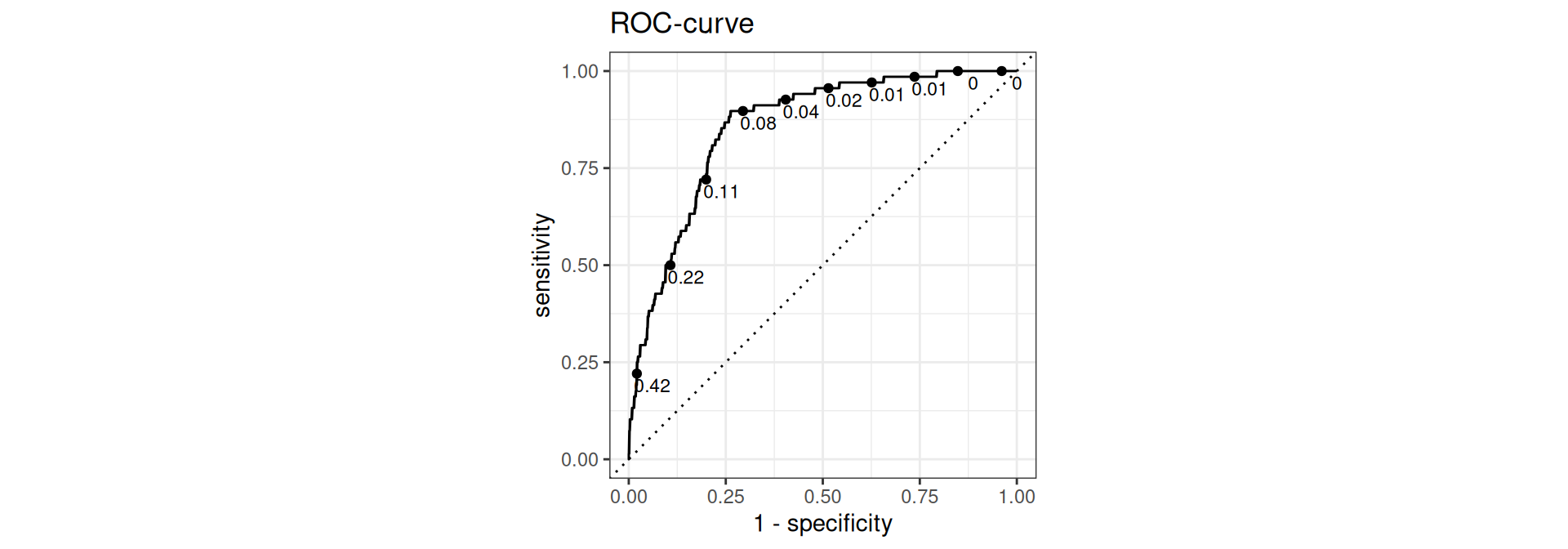
Evaluate the performance
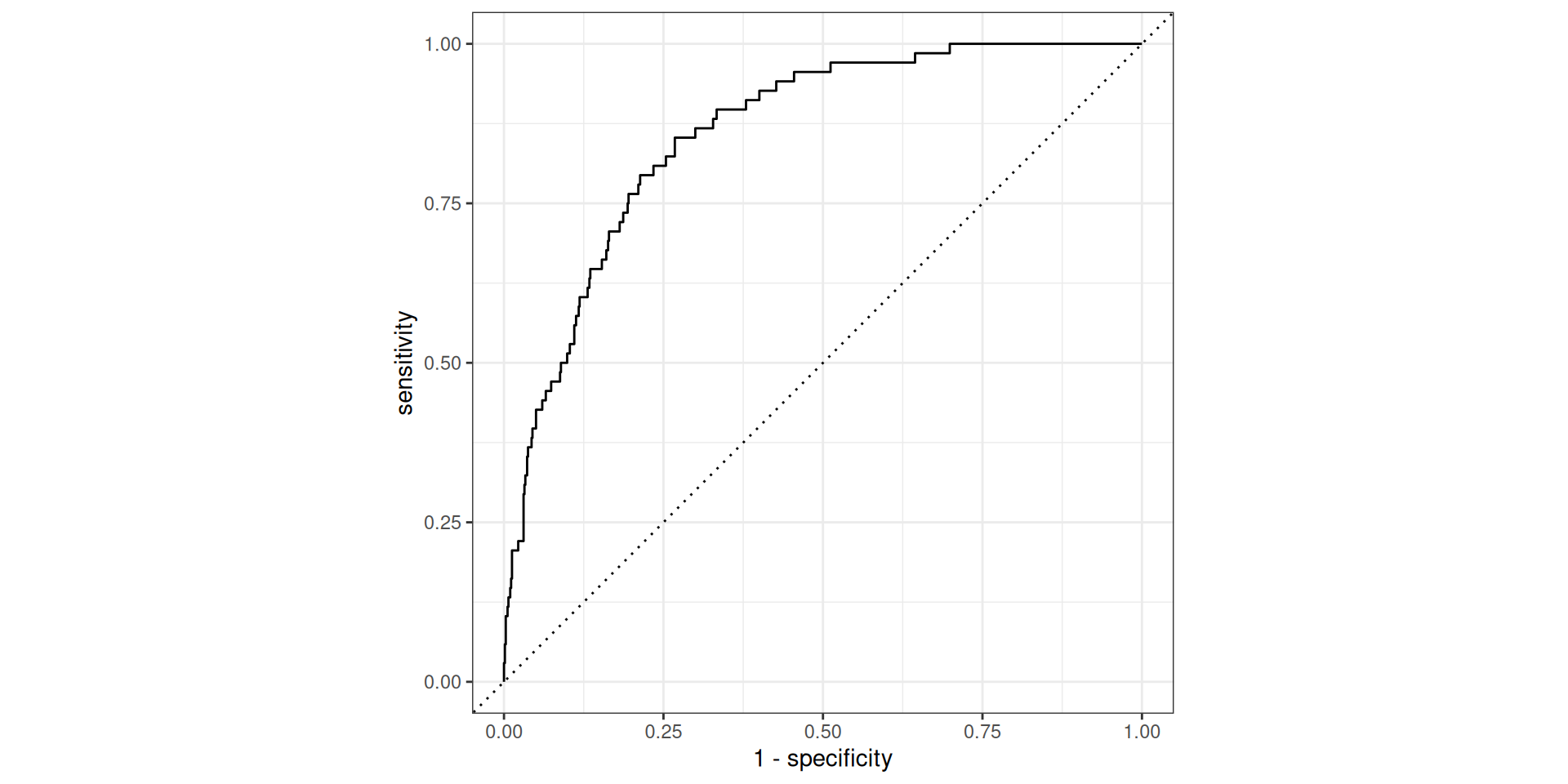
Evaluate the performance
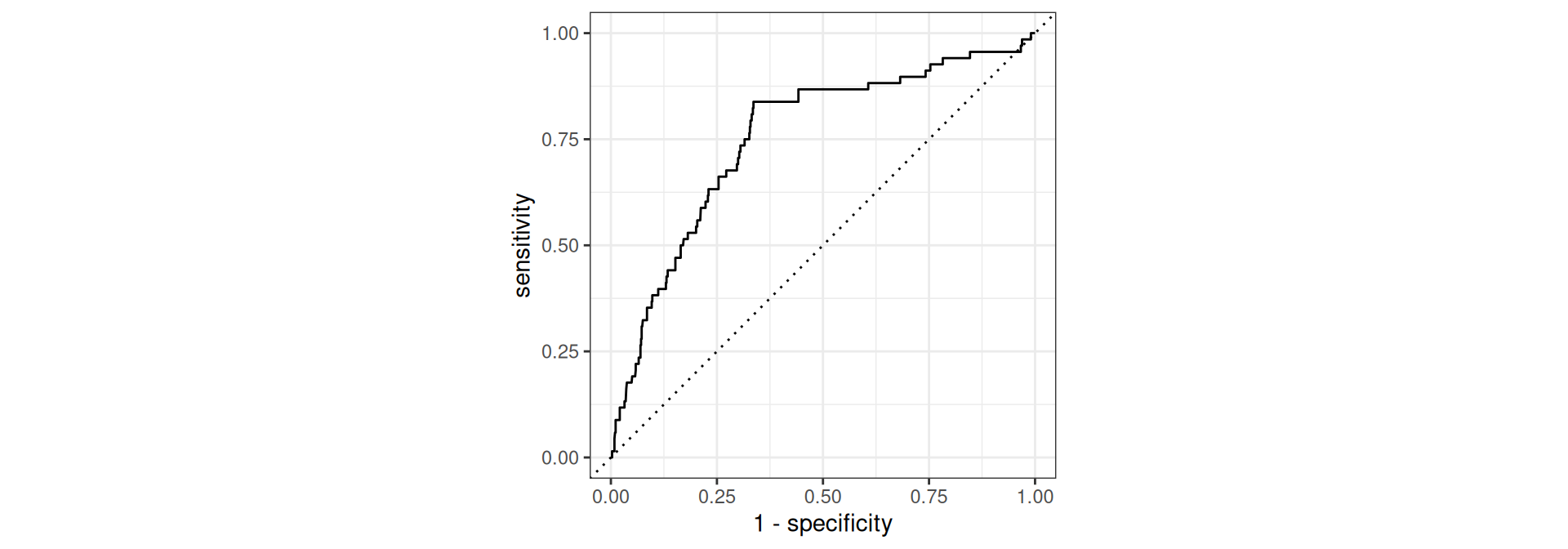
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 roc_auc binary 0.753Conclusion: It is not as good compared to AUC 0.86
Penguins: Evaluate Performance
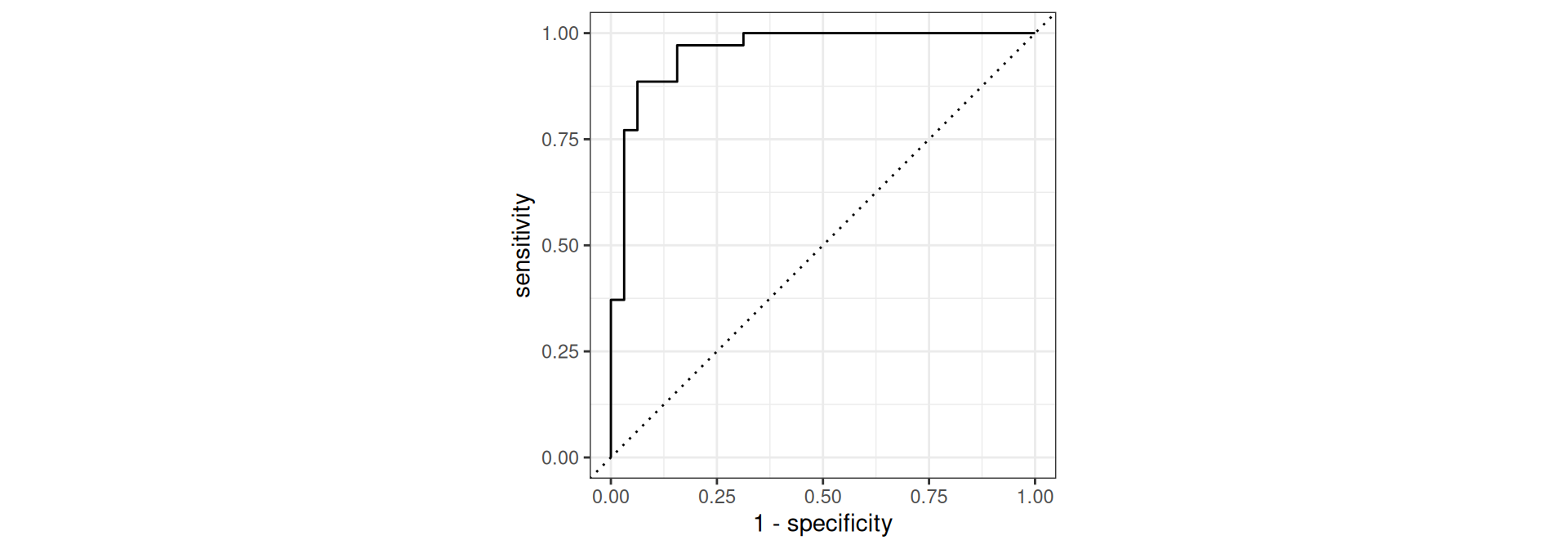
Penguins: Cutoff probability 0.75
Confusion matrix:
cutoff_prob <- 0.75
peng_pred |>
mutate(
sex = if_else(sex == "male", "Penguin is male", "Penguin is female"),
sex_pred = if_else(.pred_male > cutoff_prob, "Penguin labelled male", "Penguin labelled female")
) |>
count(sex_pred, sex) |>
pivot_wider(names_from = sex_pred, values_from = n) |>
select(1,3,2) |> slice(c(2,1)) |> # reorder rows and cols to fit convention
knitr::kable()| sex | Penguin labelled male | Penguin labelled female |
|---|---|---|
| Penguin is male | 29 | 6 |
| Penguin is female | 2 | 30 |
Sensitivity: 29/(29+6) = 0.829
Specificity: 30/(30+2) = 0.938
