W#12: Matrices, Probability, Random Variables in Data Science
Matrices in Data Science?
- Matrices are the basic data structure for many algorithms in data science. For examples
- Principal Compontent Analysis (PCA)
- Ordinary Least Squares (OLS) regression to estimate coefficients in a linear model
- The mathematical field dealing with matrices is called Linear algebra.
- A linear function \(f: \mathbb{R}^n \to \mathbb{R}^m\) can be represented by an \(m\)-by-\(n\) matrix.

Matrices and Vectors
The elements1 of an \(m\)-by-\(n\) matrix \(A\)

A matrix can be interpreted
- as \(n\) column vectors of length \(m\) and
\(\downarrow\dots\downarrow\) - as \(m\) row vectors of length \(n\). \(\begin{array}{c}\rightarrow \\[-5mm] \vdots \\[-5mm]\rightarrow\end{array}\)
In R and python, a vector is not specified as row or columns. In matrix terminology a
column vector is a \(m\)-by-1 matrix \(\left[\begin{array}{c} a_{1} \\ \vdots \\ a_{m}\end{array}\right]\)
row vector is a 1-by-\(n\) matrix \(\left[\begin{array}{c} a_{1}\ \cdots\ a_{n}\end{array}\right]\)
Convention: If a vector is not specified as row or column it is usually treated as columns if that is relevant.
Matrix Multiplication
- Matrix multiplication \(A\cdot B\) is a bit more complicated than addition and scalar multiplication.
- Matrix multiplication is different from multiplying numbers because \(A\cdot B \neq B\cdot A\)
- You have to think row-wise on \(A\) and column-wise on \(B\)

Length and Inner Product of Vectors
- The inner product of two vectors \(x\) and \(y\) is \(x^Ty = \sum_{i=1}^n x_i y_i\).
- In \(A\cdot B\) each element of the new matrix is an inner product of a row of \(A\) and a column of \(B\).
- The length of a vector \(x\) is \(\|x\| = \sqrt{x^Tx} = \sqrt{\sum_{i=1}^n x_i^2}\).
- The length of a vector is the square root of the inner product of the vector with itself.
- This is the Euclidean distance (derived from Pythagorean theorem)
- The length of a vector is the square root of the inner product of the vector with itself.
- Think of an inner product as relating the length of the vectors and their angle like this

(In the graphic \(x\cdot y\) stands for \(x^Ty\))
Some basic probability rules
We can compute the probabilities of all events by summing the probabilities of the atomic events in it. So, the probabilities of the atomic events are building blocks for the whole probability function.
\(\text{Pr}(\emptyset) = 0\)
For any events \(A,B \subset S\) it holds
- \(\text{Pr}(A \cup B) = \text{Pr}(A) + \text{Pr}(B) - \text{Pr}(A \cap B)\)
- \(\text{Pr}(A \cap B) = \text{Pr}(A) + \text{Pr}(B) - \text{Pr}(A \cup B)\)
- \(\text{Pr}(A^c) = 1 - \text{Pr}(A)\)

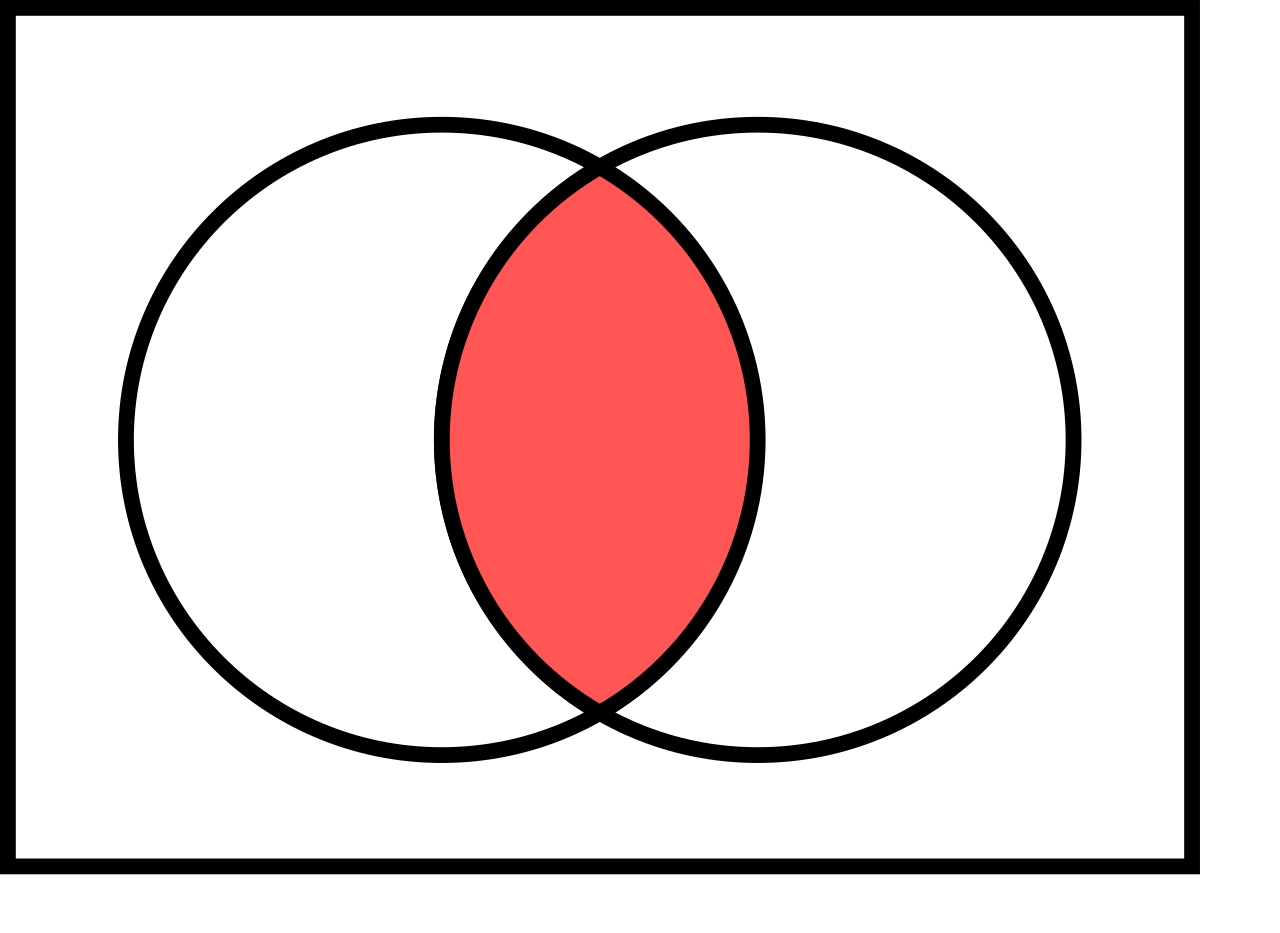

Recap from the motivation of logistic regression: When the probability of an event is \(A\) is \(\text{Pr}(A)=p\), then its odds (in favor of the event) are \(\frac{p}{1-p}\). The logistic regression model “raw” predictions are log-odds \(\log\frac{p}{1-p}\).
Conditional probability
Definition: The conditional probability of an event \(A\) given an event \(B\) (write “\(A | B\)”) is defined as
\[\text{Pr}(A|B) = \frac{\text{Pr}(A \cap B)}{\text{Pr}(B)}\]
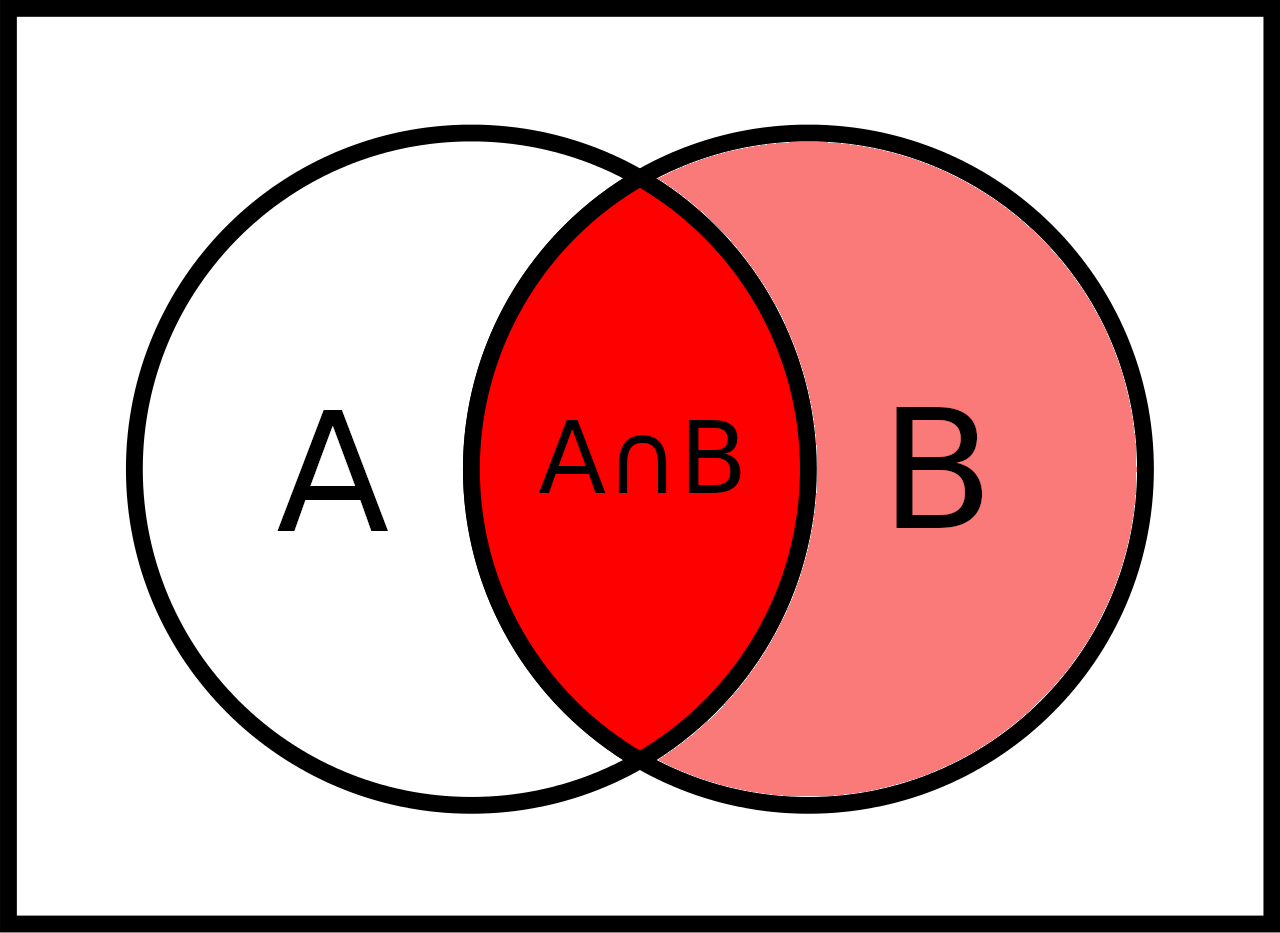
We want to know the probability of \(A\) given that we know that \(B\) has happened (or is happening for sure).
Two coin flips: \(A\) = “first coin is HEAD”, \(B\) = “one or zero HEADS in total”. What is \(\text{Pr}(A|B)\)? \(A\) = {HH, HT}, \(B\) = {TT, HT, TH} \(\to\) \(A \cap B = \{HT\}\)
\(\to\) \(\text{Pr}(A\cap B) = \frac{3}{4}\), \(\text{Pr}(A\cap B) = \frac{1}{4}\)
\(\to\) \(\text{Pr}(A|B) = \frac{1/4}{3/4} = \frac{1}{3}\)
Confusion Matrix
Confusion matrix of statistical classification, large version:
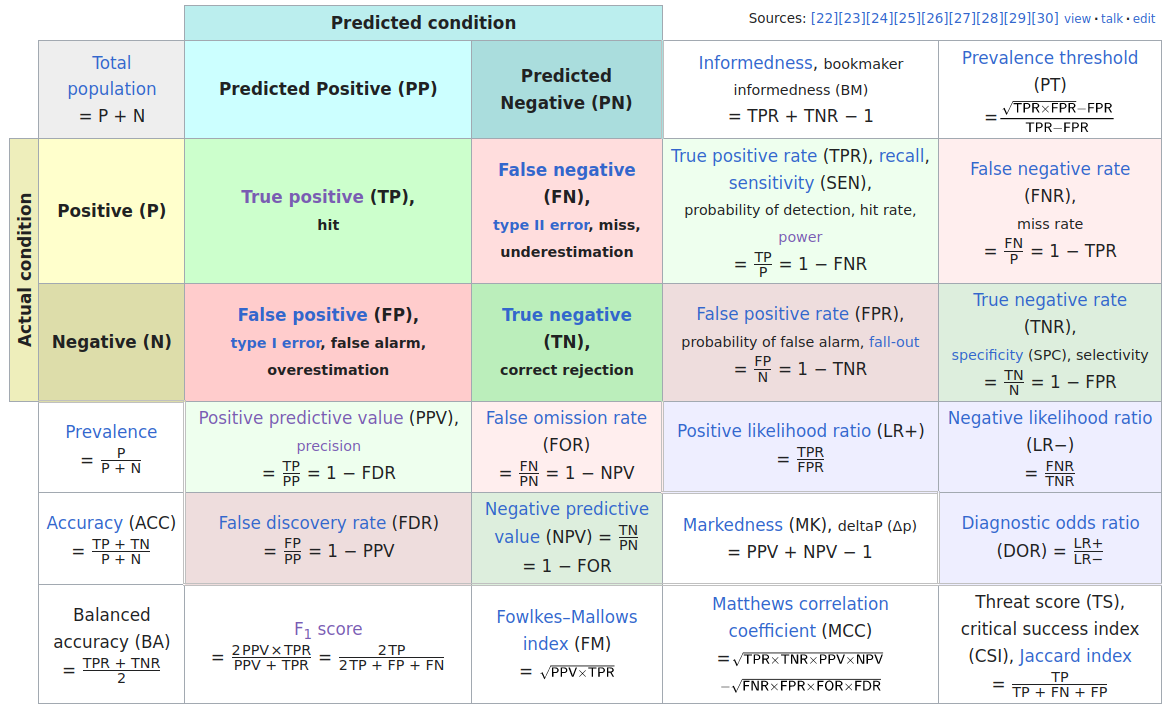
4 probabilities in confusion matrix

Sensitivity and Specificity
\(\to \atop \ \) Sensitivity is the true positive rate: TP / (TP + FN)
\(\ \atop \to\) Specificity is the true negative rate: TN / (TN + FP)
Positive/negative predictive value
\(\scriptsize\downarrow \ \) Positive predictive value: TP / (TP + FP)
\(\scriptsize\ \downarrow\) Negative predictive value: TN / (TN + FN)
Here TP, TN, FP, FN are the numbers of true positives, true negatives, false positives, and false negatives.
We can define fraction/probabilities for all the events \(P, N, PP, PTP, FP, FN, TN\) by dividing by \(n = TP + FP + FN + TN\).1
For example: \(\text{Pr}(TP) = \frac{TP}{n}\), \(\text{Pr}(P) = \frac{P}{n}\), \(\text{Pr}(PP) = \frac{PP}{n}\), …
Example: Roll two dice 🎲 🎲
Random variable: The sum of both dice.
Events: All 36 combinations of rolls 1+1, 1+2, 1+3, 1+4, 1+5, 1+6, 2+1, 2+2, 2+3, 2+4, 2+5, 2+6, 3+1, 3+2, 3+3, 3+4, 3+5, 3+6, 4+1, 4+2, 4+3, 4+4, 4+5, 4+6, 5+1, 5+2, 5+3, 5+4, 5+5, 5+6, 6+1, 6+2, 6+3, 6+4, 6+5, 6+6
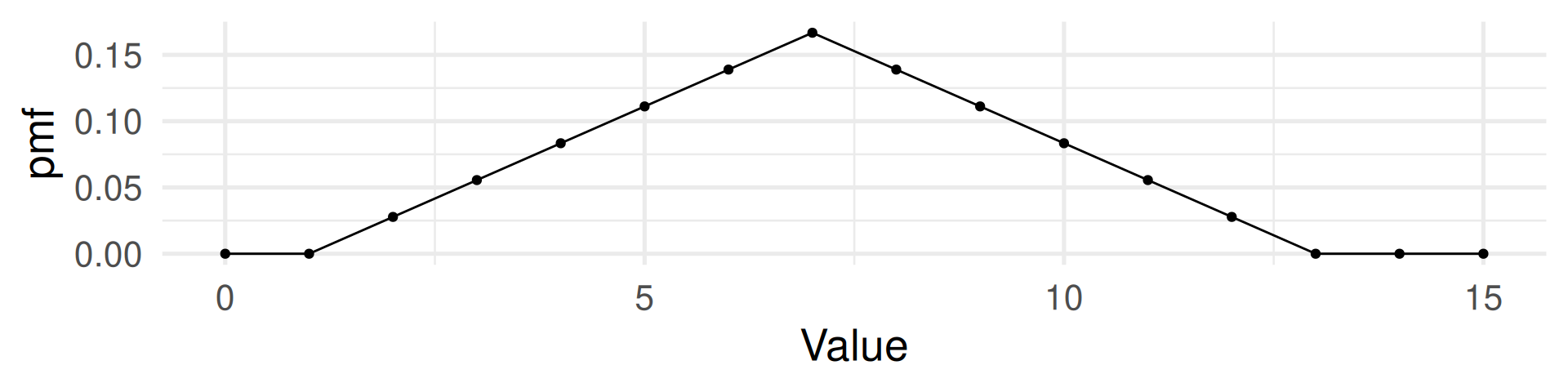
Possible values of the random variable: 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 (These are numbers.)
Probability mass function: (Assuming each number has probability of \(\frac{1}{6}\) for each die.)
\(\text{Pr}(2) = \text{Pr}(12) = \frac{1}{36}\)
\(\text{Pr}(3) = \text{Pr}(11) = \frac{2}{36}\)
\(\text{Pr}(4) = \text{Pr}(10) = \frac{3}{36}\)
\(\text{Pr}(5) = \text{Pr}(9) = \frac{4}{36}\)
\(\text{Pr}(6) = \text{Pr}(8) = \frac{5}{36}\)
\(\text{Pr}(7) = \frac{6}{36}\)
Examples of data distributions
Discrete
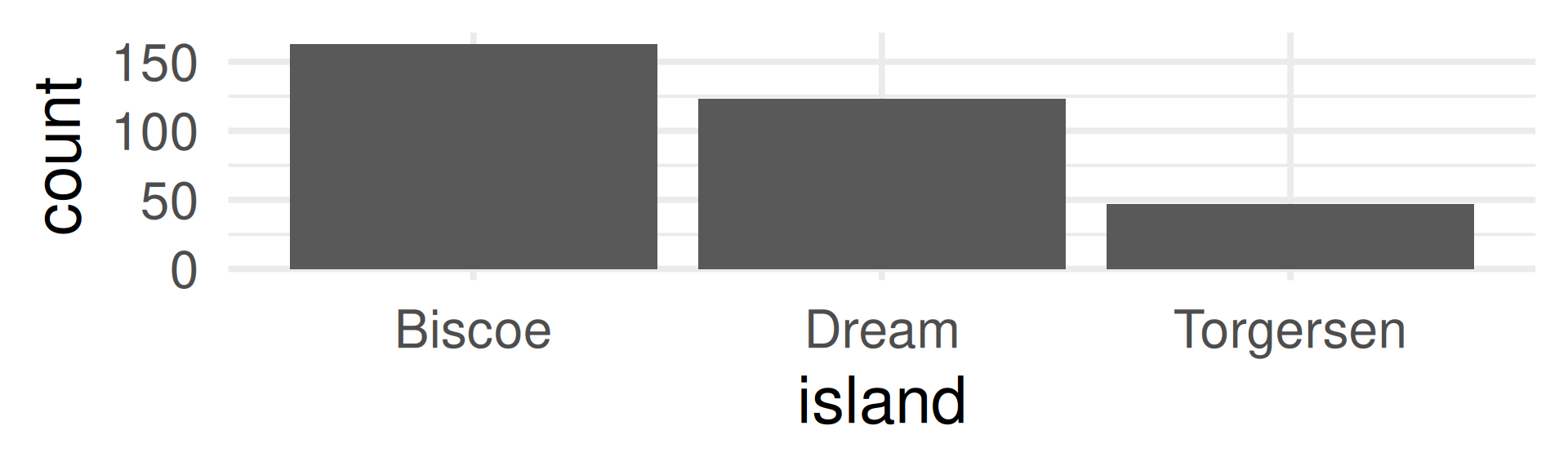
Technically island is cannot be interpreted as a random variable because its values are not numbers, but we also speak about the distribution of the variables.
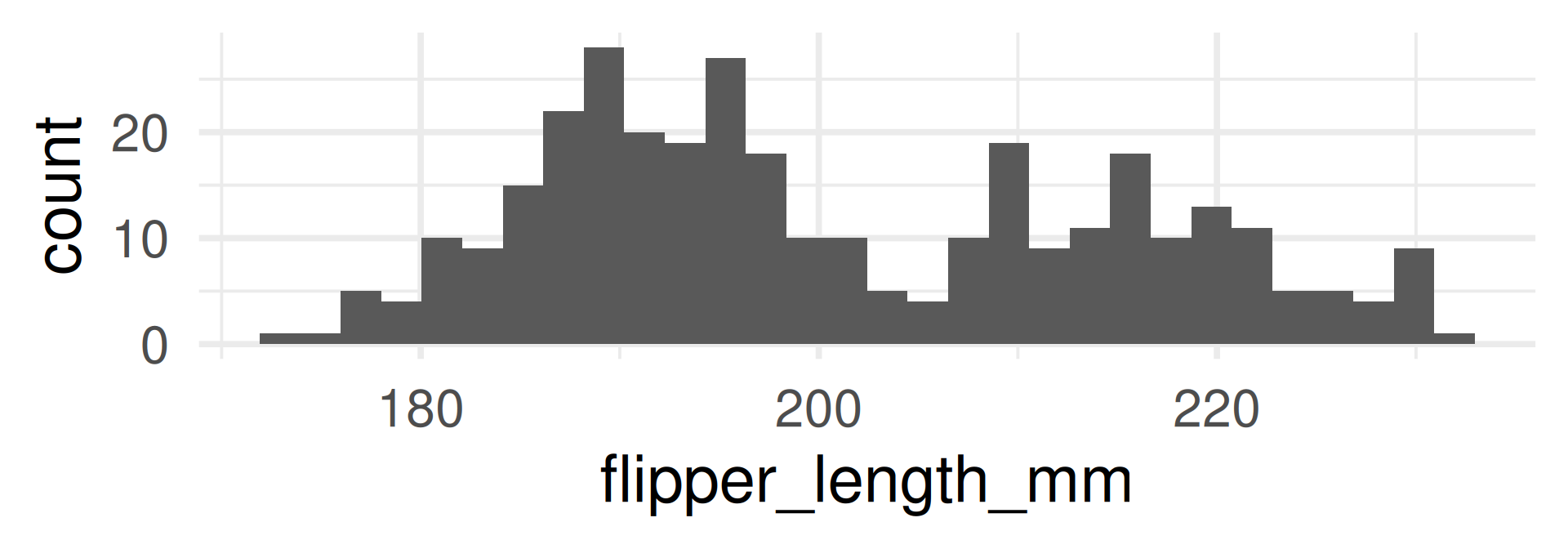
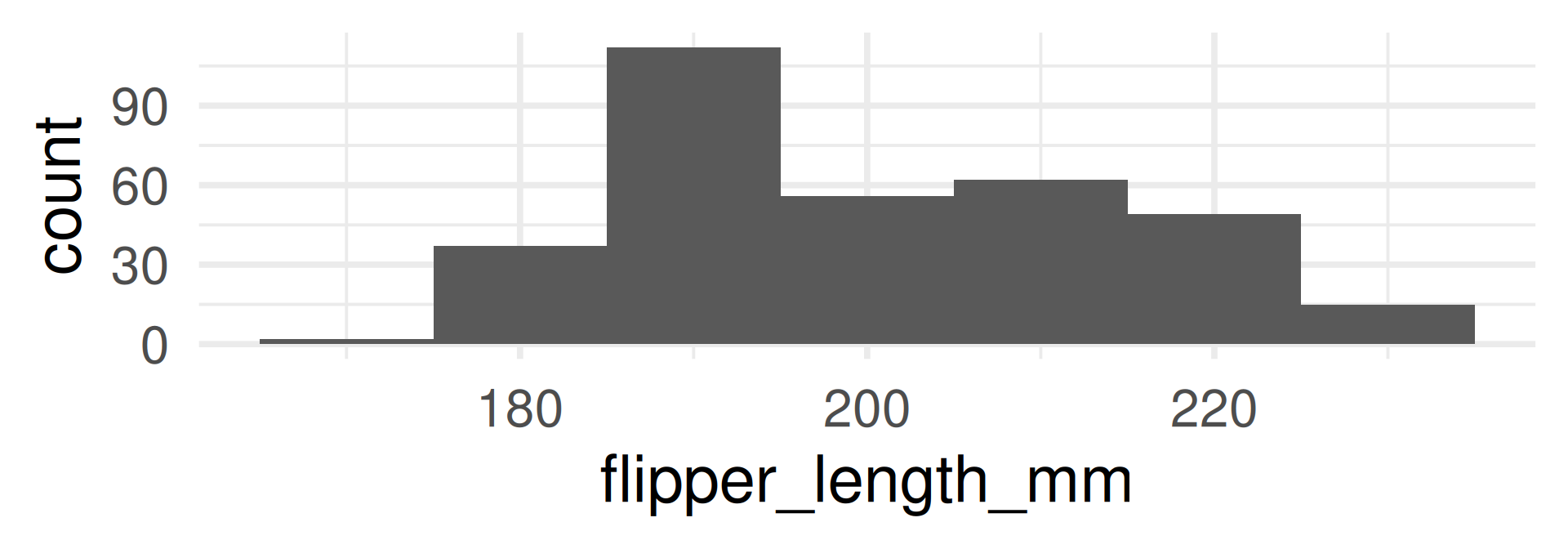
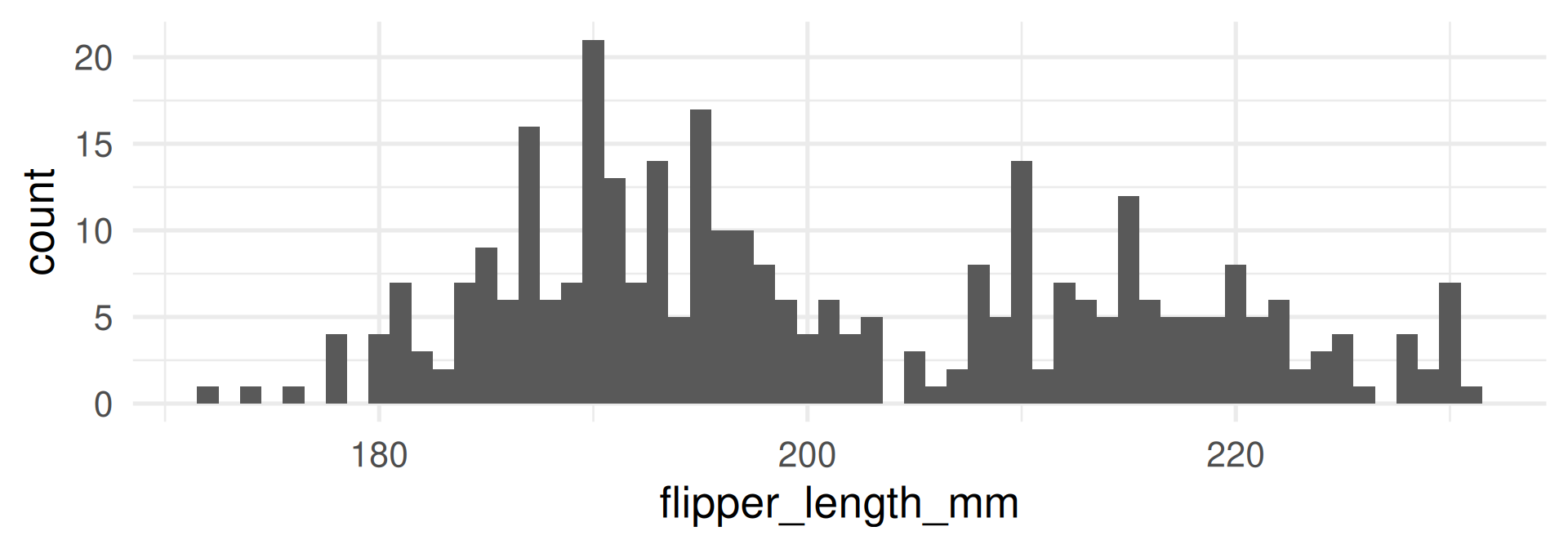
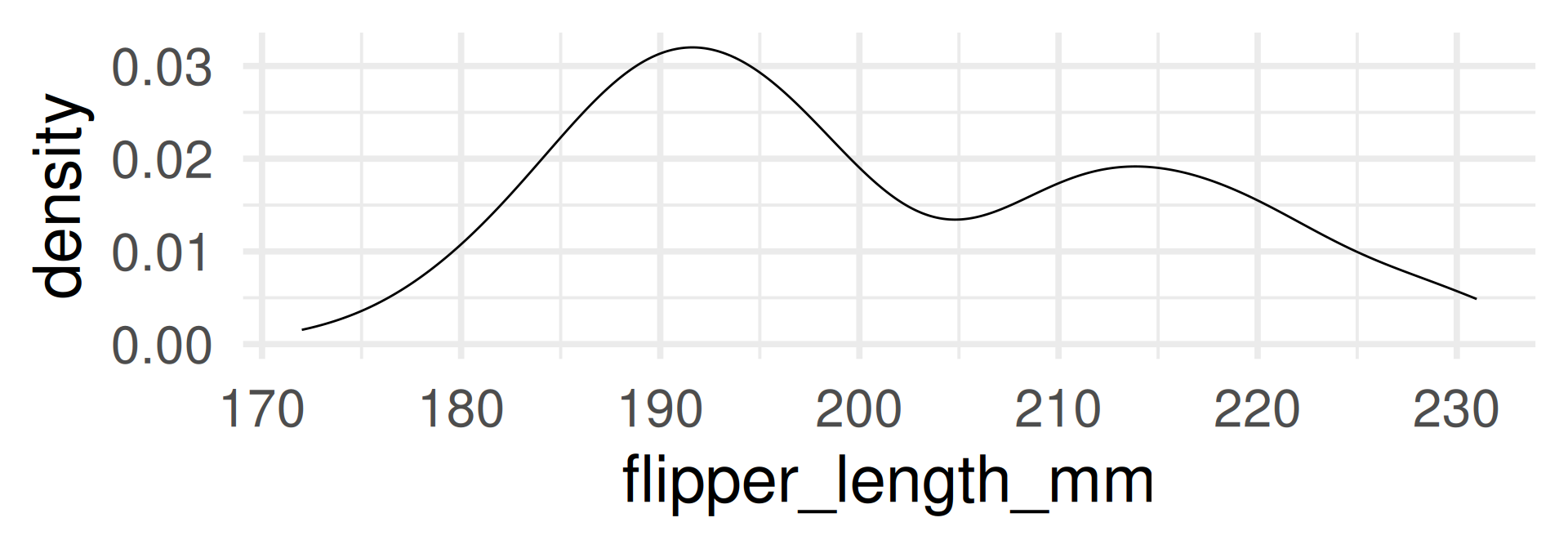
Density plot
- The density plot is a smoothed version of the histogram.
- Each data point is replaced by a kernel (e.g. a normal distribution, see later) and the sum of all kernels is plotted.
With automatic bandwidth (bw)
Distribution functions are vectorized!
Compute the p-value:
[1] 0.001455578 0.010027317 0.033981465 0.075514366[1] 0.1209787Plotting the probability mass function
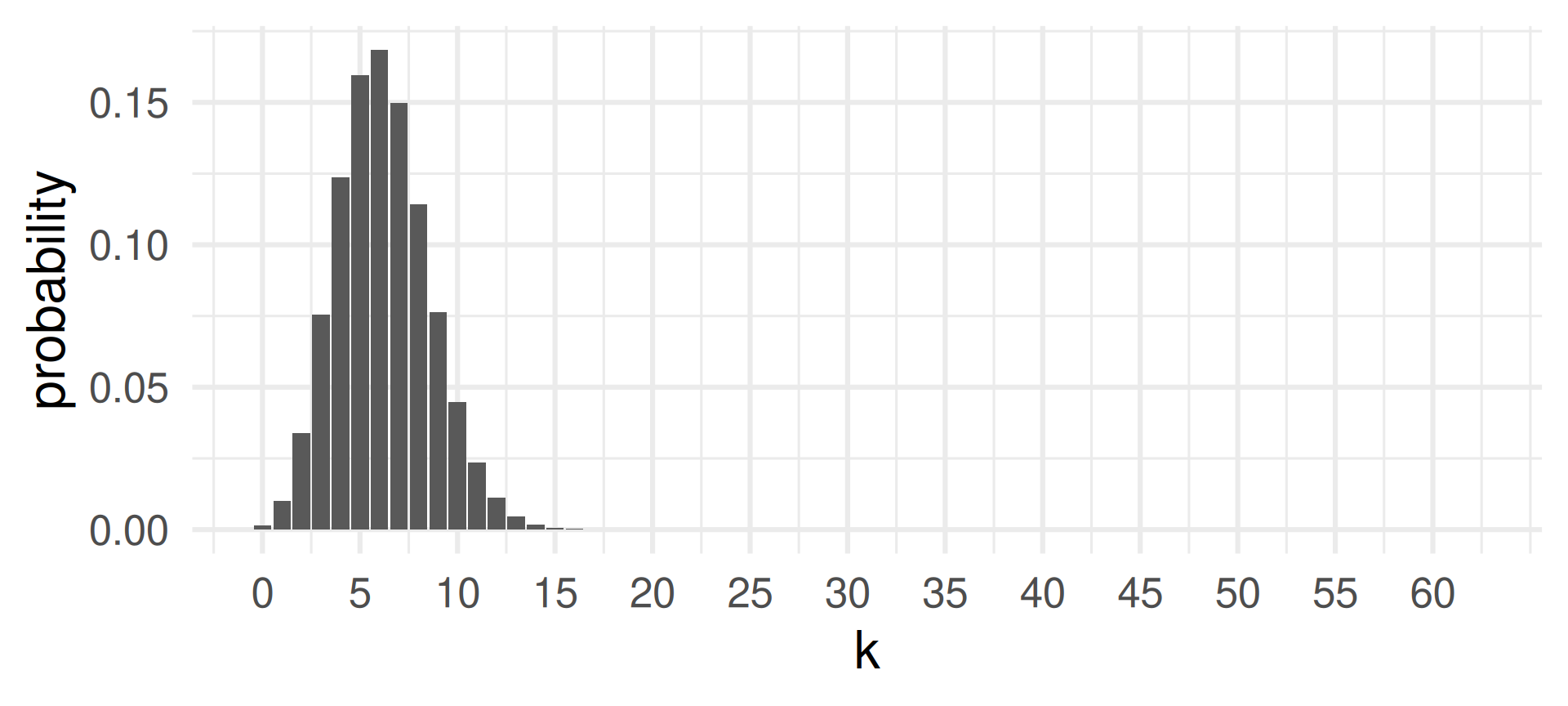
See that the highest probability is achieved for \(k=6\) which is close to the expected value of successes \(E(X) = 6.2\) for \(X \sim \text{Binom}(62,0.1)\).
Other plots of binomial mass function
Changing the sample size \(n\) when the success probability \(p = 0.1\) and the number of successes \(k=3\) is fixed:
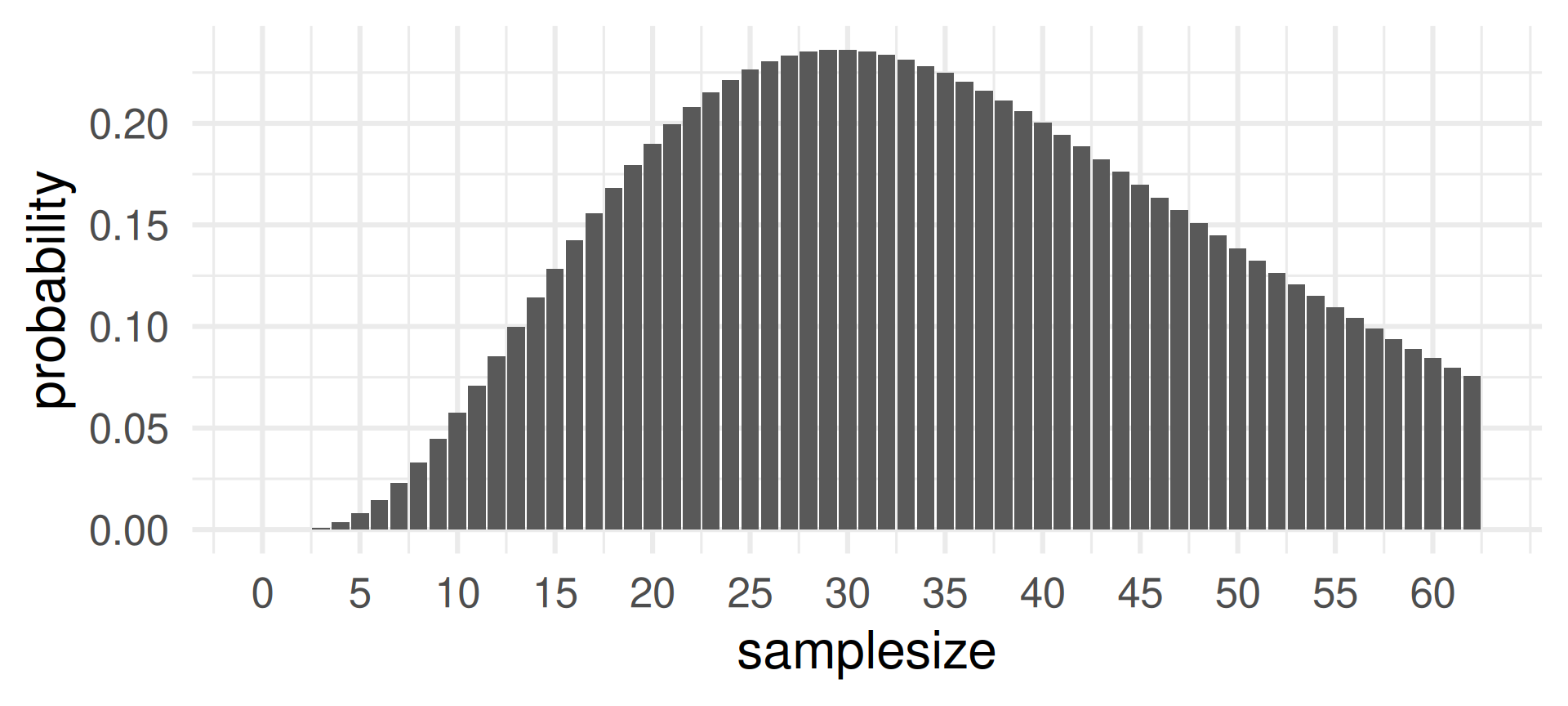
The probability of 3 successes is most likely for sample sizes around 30. Does is make sense?
Yes, because for \(n=30\) the expected value for probability \(p=0.1\) is \(3 = pn = 0.1\cdot 30\).
Other plots of binomial mass function
Changing the sample size \(p\) when the sample size \(n = 62\) and the number of successes \(k=3\) is fixed:
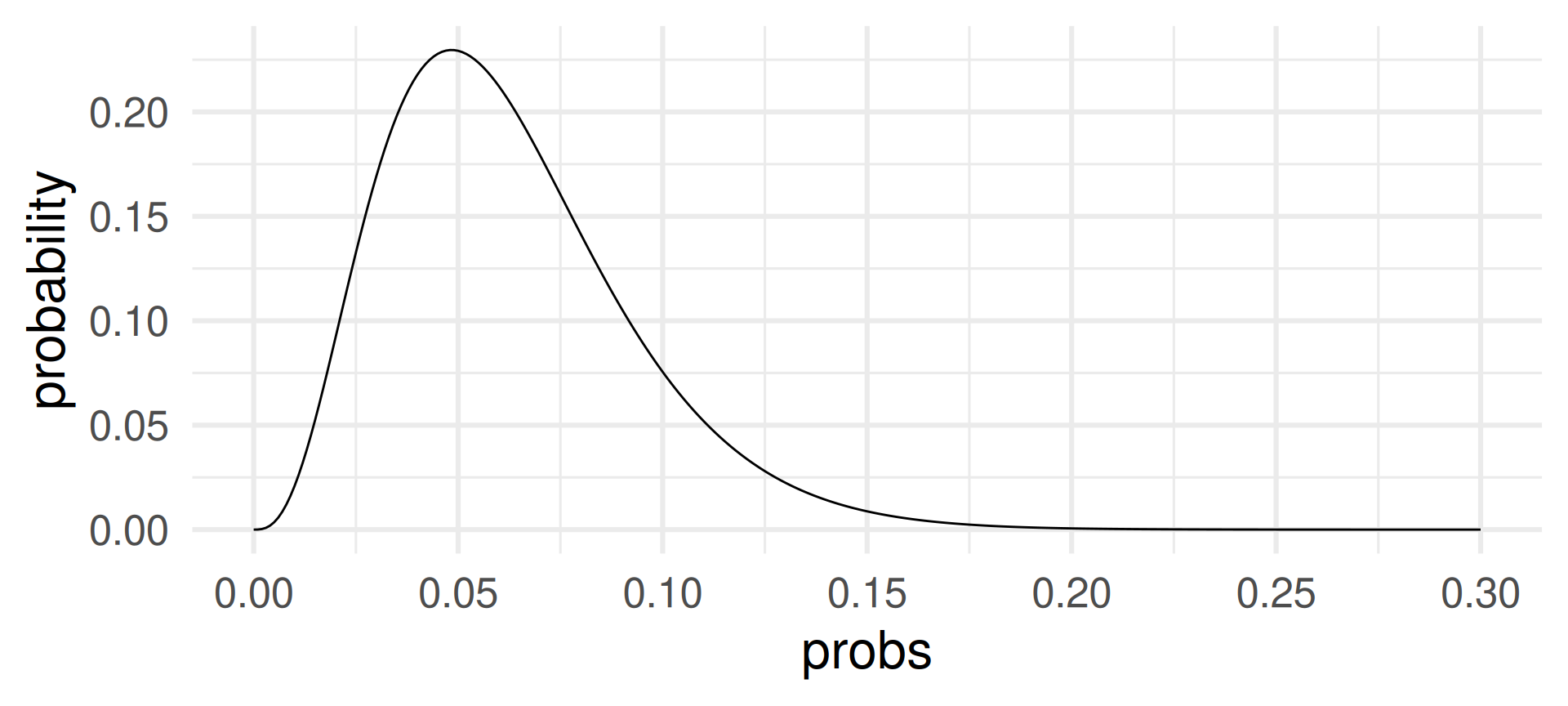
The probability of 3 successes in 62 draws is most likely for success probabilities around 0.05.
For \(p=0.05\) the expected value for \(n=62\) is \(pn = 0.05\cdot 62 = 3.1\).
